ʱ�� 4 ���£�Kimi �Ƴ������¿�Դģ�� K2 �������汾����K2 Thinking ģ�ͣ�Kimi ����Ϊֹ��ǿ�Ŀ�Դ˼��ģ�͡�
1T ������MoE �ܹ���32B ���ԭ�� INT4 ������256k �����ģ�����֧�ֹ��� GPU��
�ٷ�����ɼ���ʾ��K2 Thinking �ڡ��������Ŀ��ԡ��������У���������Եı��ִﵽ�� SOTA ˮƽ���������ǿ�Դ����K2 Thinking �IJ��Գɼ�������ͬ���ͱ�Դģ�͡�
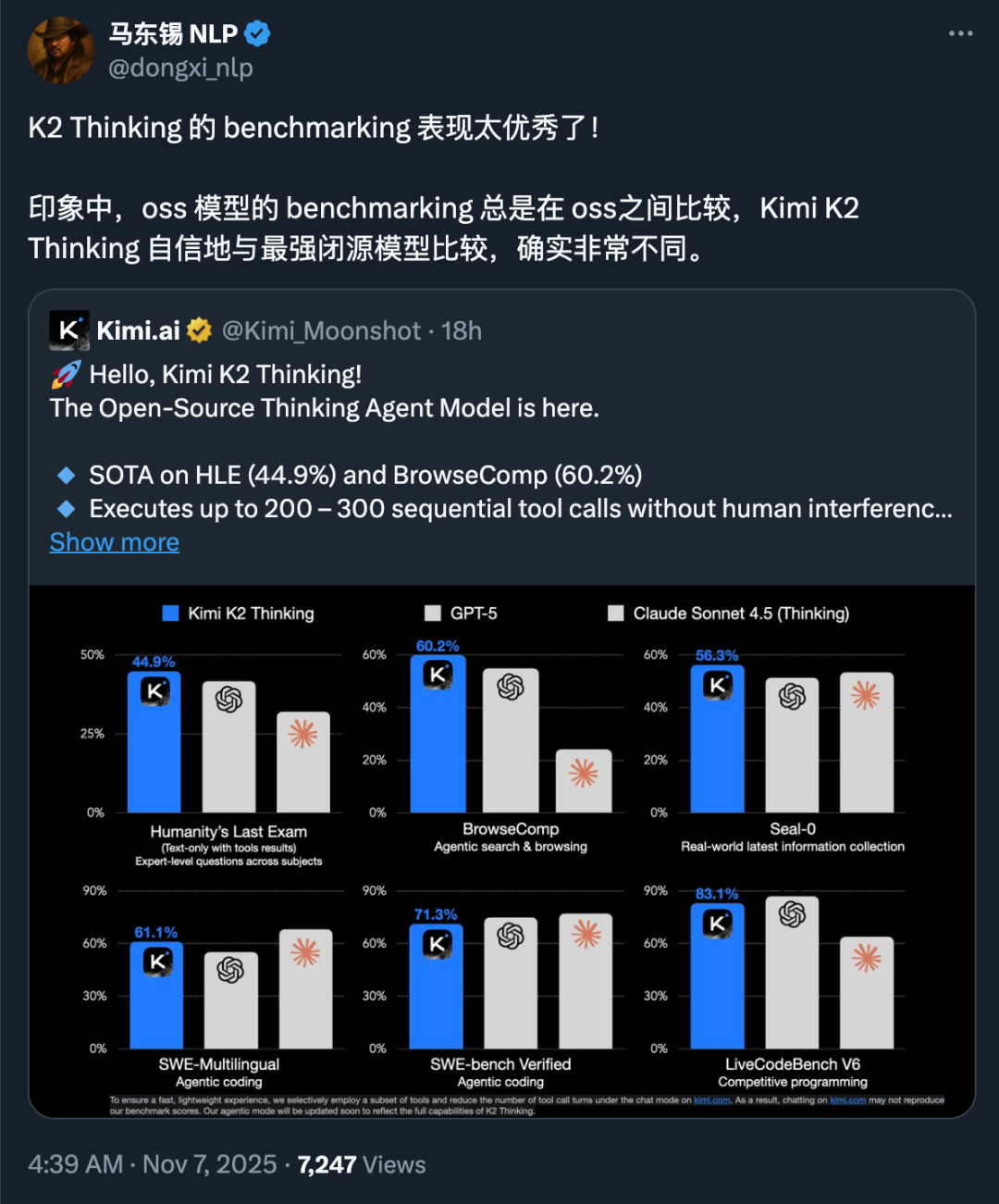
��Ƚ� K2 ģ�ͣ�K2 Thinking ģ�������˹���Ԥ����������ʵ�ָߴ� 300 �ֵĹ��ߵ��úͶ���˼�����������Խ�������ӵ����⡣
�ع�ͷ�������� K2 �� K2 Thinking���ӡ�ģ�ͼ� Agent������ģ�ͼ� Thinking Agent����Kimi �������Լ��Ķ��ؼ���˼�����жϣ�����Դ��������£���������������ŷ�� AI ��ͷ�ĵ�·��
������ô�������е���Ѫ���ļ��ӸС�
01
K2 Thinking��
��������Ե� SOTA ģ��
����Ҧ˳���ڡ�AI �°볡������˵�����˹����ܵ��°볡���������ڿ�ʼ���������ص�ӽ������ת�Ƶ��������⡣�������ʱ������������ѵ������Ҫ����
ģ���������������ĵ��£�������ñ�����������Ҫ��
�� NMLU��GPQA �ȴ�ͳ�������Ѿ�����Ч����ģ��������ʱ���������Ŀ��ԣ�Humanity's Last Exam����� HLE���� 2025 ��Ӧ�˶���������һ��ּ�����������������Ĵ�ģ�͵������Ļ����Լ����� Center for AI Safety �� Scale AI ���ϴ������������ݼ��������������� 2025 �� 3 �� 4 ��ȷ��Ϊһ�װ����� 2500 ��ǰ��ѧ���������⣬��Щ��ֲ��� 100 �����ͬ��ѧ�������� 50 ������ҵĽ� 1000 ��ѧ��ר�ҹ��ס�
������ʹ�ù��ߡ���������Python������������ߵ�ͬ������£���� Text-Only �����ݼ��IJ��Խ���У�Kimi K2 Thinking �������������ȡ���� 44.9% �� SOTA �ɼ���
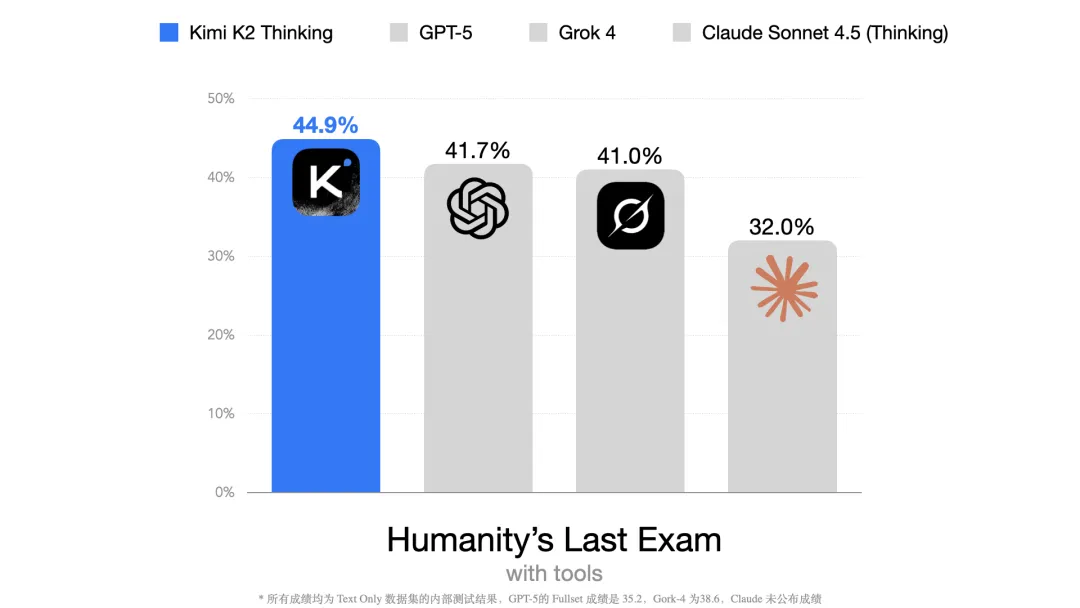
HLE ���Լ��������ʱ���콢ģ�͵������������� 20%�����˽����һ������ﵽ�˳��� 40% �ijɼ��������ݵ� Scaling Law Ч����С�ĵ��£�ģ�͵�����ȷʵ����һֱ�����С�
�������˿�Դģ�ͳ�����Դģ�͵�һĻ��
��ȥ�ٷ�����ʾ�����⣬����Ҳ�����ˡ��w�ص� AI �����䡹�����������ġ�����ý�����ߵ����⣬��ֻ�Ǵ���������ǿ�ˣ������Ե��ǣ����������ۺ�������������ˡ�
02
������֮���������˽��ּ�
�ص� 4 ����ǰ���� K2 ������ʱ���ܶ��˵ĵ�һ�ɻ��ǡ�����Ȼ���Ǹ�����ģ�ͣ�
�� DeepSeek R1 �Ѿ���Ϊȫ�������¼�ʱ��һ�������ģ�͵Ŀ�Դ���ܴ������ķ����أ�
Kimi ��ʱ����Ļش��Ǿ۽� Agent�����ܸ��õ��ù��ߵ� Agent ģ�͡���������Kimiһλ�о�Ա�������е�֪����ʵ�� K2 ����ǰ�������Ѿ�����һ������� thinking ģ�ͣ����� K2����ʱ��ֻ�ȷ����� Agent ��ǰ��ء�
8 �·���С�B����ֲ��IJɷ��У���ֲ��������Ϊ������ģ�ͷ�ʽ�У�ѡ���˺��ߡ�
��һ���dz�˼��������ģ�ͣ�Reasoning Model������ o1 ��Ϊ��һ���������Ĵ����������ϣ���ͨ����ģ���ڹ��������ܶೢ�Ժͷ�˼����˼�������ص㡣��������һ��������֮�ԡ���brain in a vat����������Ҫ����罻������
��������һ������Ҫ�ķ�ʽ�����ǻ��ڶ��ֵ� Agent�������壩ǿ��ѧϰ��ʽ������ͨ��ǿ��ѧϰ����ѵ�������� Agentic ģ�ͣ������ص��ǻ��������ཻܶ������
����������������ָ����ͬһ���������ǣ�test-time scaling������ʱ��չ������˼�ǣ������ڲ���ʱ������������ʱ���������õĹ�ģ������
Kimi ��ʱѡ���˵ڶ��ַ�ʽ����������������Ȼ����������˼����Ҳ���ǽ���� K2 Thinking��
һ�����˽��ּܵġ�����֮�ԡ�������ֲ��Ļ�˵������������һ���ӡ�����֮�ԡ���ɿ��Ը����罻������Ϊ��ν Agent ����Ҫ�����������������Զ��ֵ�ʹ�ù��ߡ�
�������ؼ��㣺һ���Ƕ��֣�һ���ǹ��ߡ�
���־����������ܶ�Σ��� test time scaling������ʱ��չ����һ�ַ�ʽ��������������������ԡ����ⲿ����ķ�ʽ����
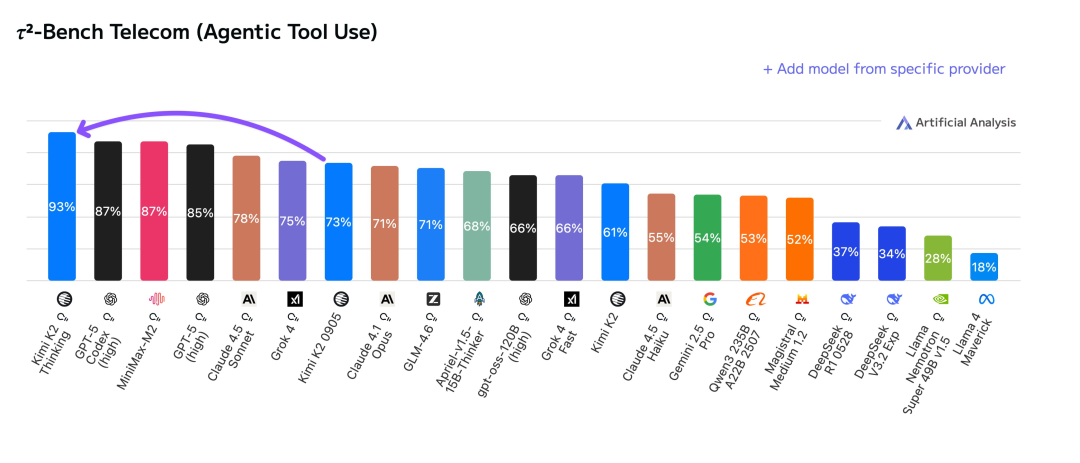
K2 Thinking ���ù��ߵ������н�һ������
��������֮�ԡ����˽��ּܣ�ģ�͵����������ʵ����������Բ���������ʵ�� 300 �ֹ��ߵ��úͶ���˼����������ʵ���˸�ǿ�� Agent ���������ܡ�
������һ����OpenAI ��ǰ�����õ� AI �� L1-L5 �ķּ���L3��Agent �����壩���ܲ���Ŀ�������⡣
��Ȥ���ǣ��� K2 Thinking �� API ����˵���п��Կ�����ģ�͵Ķಽ���ߵ��ã���Ҫ�������������е�˼�����ݣ�reasoning_content �ֶΣ����ظ�ģ�ͽ��ж�����������������������ԡ�
������������������ Claude �ġ�extended thinking������չ˼������ͬ��Ҳ��֧�ְ����������������������衣
�ڵ��£�����һ�ַǹ�ʶ�ļ���˼·��OpenAI �� GPT ϵ�к� Google �� Gemini ģ�Ͷ�û��֧��������ܡ�
03
��Դ�����µ�����
�� K2 Thinking ģ�ͷ����������� X�����أ��Ͽ�����һ����Ȥ��ͼ��
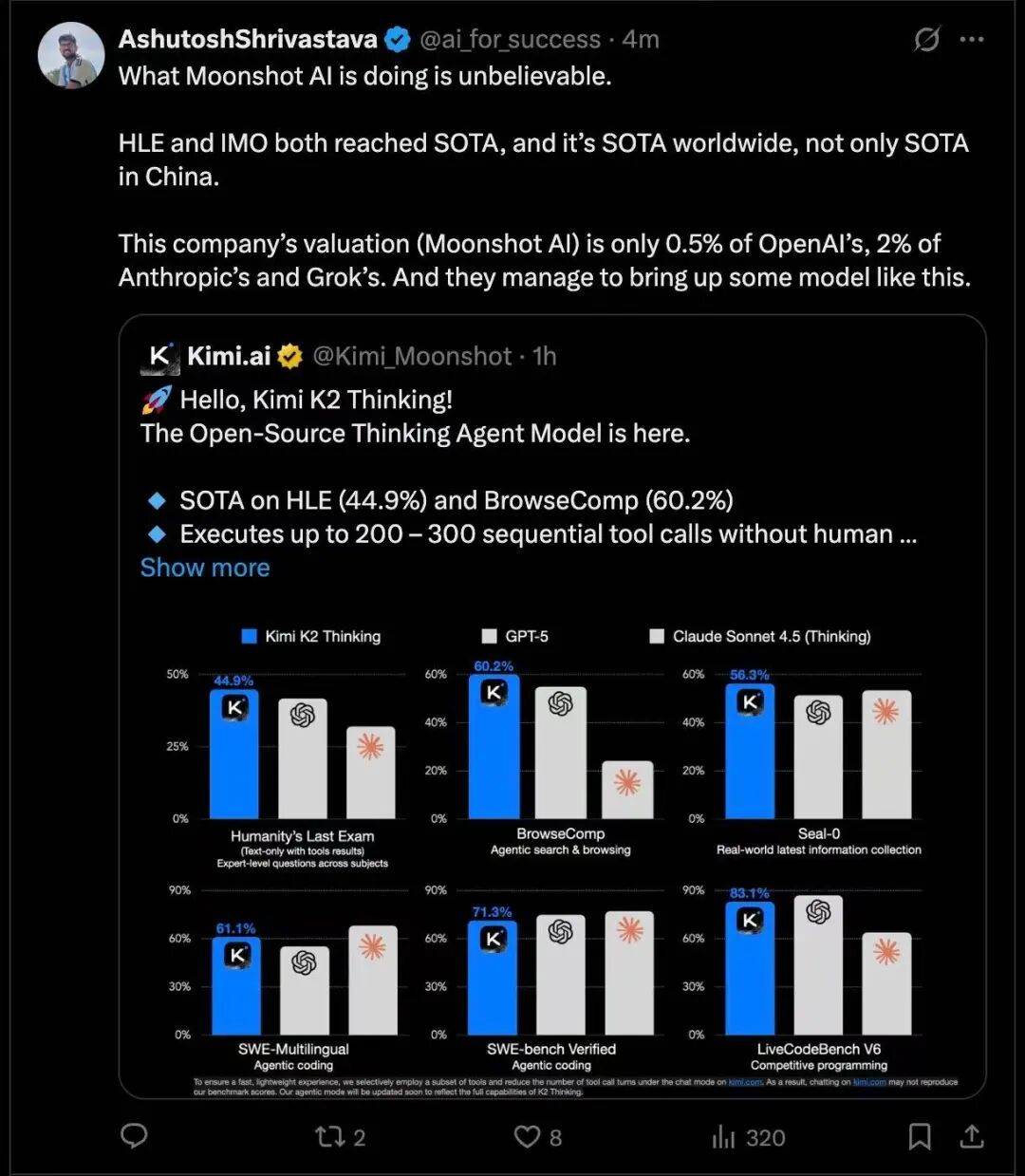
������λ������˵������ HLE �ϴﵽ��ȫ�� SOTA ������ K2 Thinking��������˾��֮����Ŀǰ�Ĺ�ֵ�� OpenAI �� 0.5%���� Anthropic �� Grok �� 2%��
�������ǿ����ø���ϸ��һ����������һ���Աȡ�
Kimi ȥ��Ĺ�ֵ�� 33 ����Ԫ������������������е������ʣ������¹�ֵ���ڼ�ʮ����Ԫ����
����˹�˵� Grok��xAI�������� 2025 �� 9 �µף���ֵԼΪ 2000 ����Ԫ������˳�㿴���������ҵĹ�ֵ���������ɽ��� 9 �·� F �� 130 ����Ԫ�����ʺ�Anthropic Ŀǰ�Ĺ�ֵ�� 1830 ����Ԫ��OpenAI ���µĹ�ֵ�� 5000 ����Ԫ����Ϊȫ�����ֵ��˽Ӫ��˾֮һ��
���ͬʱ��xAI ӵ��Ŀǰȫ���ģ���� GPU ��Ⱥ֮һ����20 ��� H100 GPU �� Colossus �����������Ⱥ��Ա���������� 1200 �ˣ��ݹ��� Grok 4 ��ѵ���ɱ����ܴﵽ�� 4900 ����Ԫ��
�� Kimi����˾���� 200 �����ң�����ý������ѵ���ɱ�Լ 460 ����Ԫ��
���й��Ļ�ģ��˾��˵�������١�ȱ�Կ�������Դ���ϡȱ����״������̫�١���̫���� OpenAI��Google ��������ͷ��ȣ��Դ������١��ɱ�ѹ����Ҫ������������뾫ȷ�ذ�ÿһ����ִ�ж����ԡ�K2 Thinking�ڶ���˼���͵��ù��ߵ������ϳ���GTP5��Grok4�ȹ����Դģ�ͣ����й� AI ��ҵ��˾�ò��� 1% ����Դ������˶����ھ�ͷ����緭�̡�
δ�����Ƿ�������ѫ�ԡ�����ʱ������˵�����������й������˹����ܾ����л������������������ڸı䡣

















