���죬OpenAI������ô�ã������ӳ��µ��ذ���Ʒ��GPT-5.2
�ڹȸ�������������ֵ�Χ�½��£�������γ������˴��ˣ�
GPT-5.2�ٷ��ĵ���ֽ����д�ţ��ں���44��ְҵ��רҵ֪ʶ���������У�GPT-5.2 Thinking���������ٶ�������ר�ҵ�11�����ϣ��ɱ����������1%��
�����ĵ��ǣ��������ΪGDPval�IJ����GPT-5.2 Thinking�붥����ҵר������PK��70.9%�������У�AIӮ�˻��ƽ��
һλ�����������ί����AI��������̾��"������һ����רҵ�ŶӵĹ�˾�������ġ�����Ȼ����ЩС��Ҫ�ģ������ֺͽ��鶼�����רҵ��"
��ɫ������GPT5.2��ɶ����Ľ���
�����ϸ��£��ȸ�ų���Gemini 3���ڶ����������ȫ�����ȣ�һ�Ȱ�OpenAI��ô��ֲ�����
OpenAI��CEOɽķ�����������ڲ�����һ��"Code Red"����ɫ����������¼��Ҫ���Ŷ���ͣ������Ŀ��ȫ�����ChatGPT����һ�ε�����

GPT-5.2������ž��ܿ�������OpenAI��������ǰ������
��η�����GPT-5.2�������汾��
Instant���졢�ȣ��ʺ��ճ������ϡ�д�ʼ���
Thinking������������ʺϱ�̡����ݷ��������ĵ�������
Pro�����䣬����ȷ�ʣ��ʺϸ߷��վ��ߡ�
�ڱ�̻�����SWE-bench Verified�ϣ�GPT-5.2 Thinking����80%�ijɼ�������ѧ������AIME 2025�ϣ��÷�100%��
�⿴��������û�ã����ǵø����ף����������������ôͻȻ����ôǿ�ģ�
���ĵ�ǰ����ѵӪֱ���У�����ȫ�ʹ�ҷ�����Ԥѵ���Ż�������ԭ���ߴ�ҵײ�оƬ�������ʹ洢û�д���µ�����£�AI��ģ�ͽ������Ľ�����Ҫ����������ѵ����ǿ��ѧϰ��������
֪����ARC�����У�����ģ����Ҫ�����ӳ�������߳ɼ�
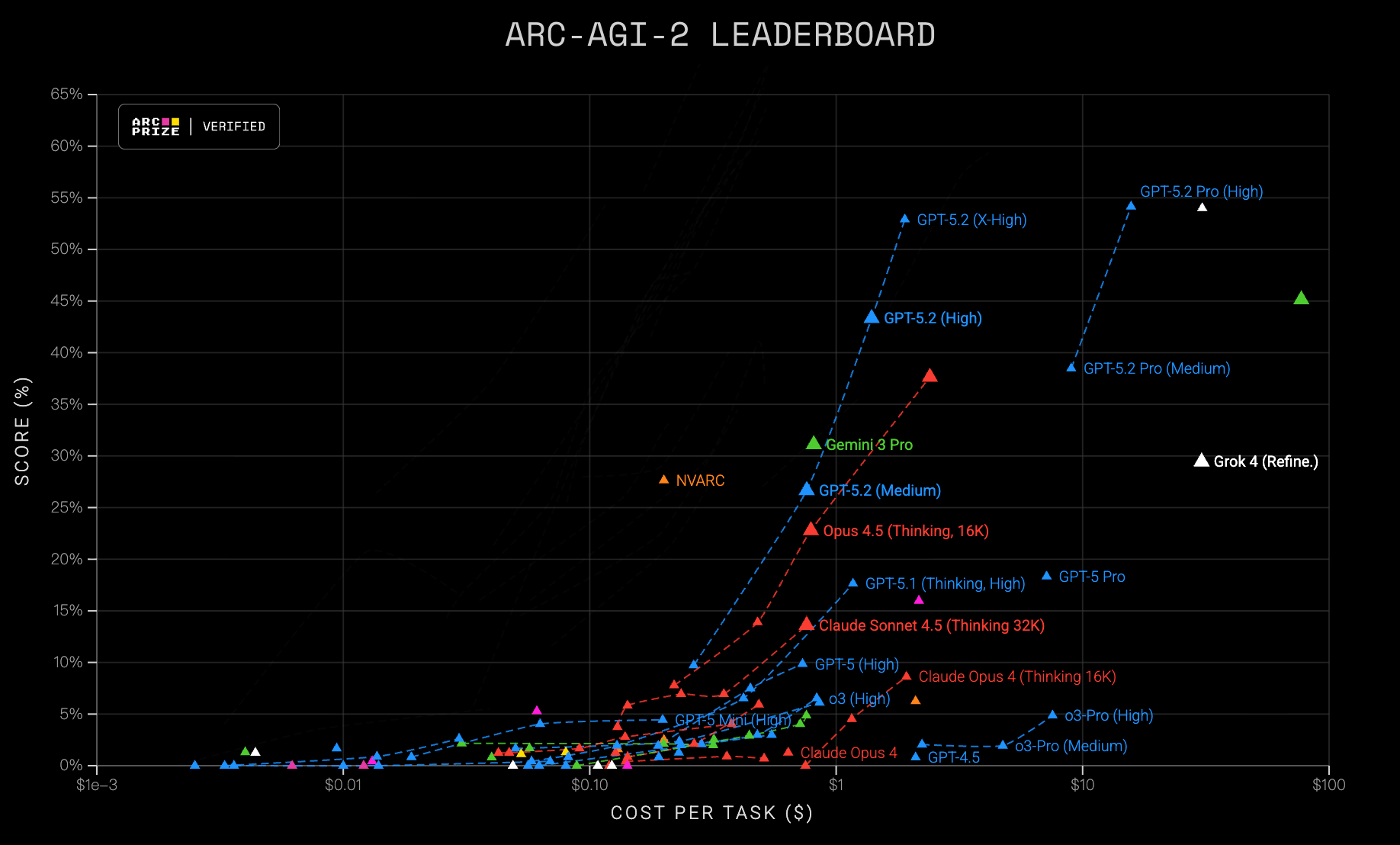
OpenAI��η�����֤������жϡ�GPT-5.2�ٷ��ĵ����������ؼ��㣺
��һ�������о����� �ĵ����ᵽ"ͨ��ѵ����ģ��ѧ�ᾫ���Լ���˼�����̡����Բ�ͬ���ԡ���ʶ���Լ��Ĵ���"
�ⱳ�����ʾ���ͨ��ǿ��ѧϰ���Ż���ģ�͵��������̣�����ѧ�������ڲ�����ݸ塱�������ǰ����������
�ڶ���ͨ������������ֱ���� ��ģ��OpenAI�ڲ����빤���IJ����У���"˼��"��ͨ�ð�GPT-5.2����Ȼ��������һ��ר����Դ����Ż��Ĵ�ֱģ�ͣ�Codex Max����
��֤����ǿ��ѧϰ���������������������ܼ������ģ���ڲ�ͬ�����ķ����ԣ���˵������ģ�����������ʦһ���������⣬����������Ӳ������⡣
˵�˻����ǣ�GPT-5.2��һ�������ı������ǿ��ѧϰ��AI��ô"��"�������������רҵ��������ѹ����ĵײ�ԭ��
������������ЩְҵΣ���ˣ�
���ˣ����������ˣ������ĵ�����ĵģ���Щ�˵ķ�����Σ�գ�
Ҫ�ش�������⣬����˵˵OpenAI������GDPval���ԡ�
GDPval��ȫ����"GDP Validation"����OpenAI��2025��9�·�����һ��������ϵ��
���ĺ���˼·��ֱ�ӣ�����AI�ȿ��Է�����ֱ�ӱ�"�ɻ�"��
OpenAI������һ��������רҵ��ʿ��ƽ����ҵ����14�꣬��������GDP��������9����ҵ��44��ְҵ��
��Щ�˳��⣬���Ķ��������ճ���������ʵ��ɵĻ����������PPT�����������ģ�͡��ż�����ֵ�����.
Ȼ����AI������ר�Ҹ���һ�飬����ר��ä����˭���ø��ã�
����������ǿ�ͷ˵�ģ�GPT-5.2 Thinking��70.9%�������У�Ӯ�˻��ƽ����ר�ҡ�
���ֲ����ǣ�AI�����Щ������ٶ��������11�����ϣ��ɱ����������1%��
��ô�������ˣ���Щ��λ��Σ�գ�
��GDPval���Ը��ǵ�44��ְҵ������֪ʶ�ܼ��Ͱ����λ����塣
Ͷ�з���ʦ��OpenAI�ڲ�������ʾ��GPT-5.2��Ͷ�г�������ʦ�Ľ�ģ�����ϣ�ƽ���÷ֱ�GPT-5.1�߳�9.3%��
�ͷ����ۺ�AI�ڹ��ߵ��ò���Tau2-bench������98.7%��ȷ�ʣ���Э�������ǩ�������١�������λ���ŵȸ������̡�
����Ա������������������Windsurf�Ѿ���GPT-5.2����Ĭ�ϵ�����
����½�ɫ����"ִ����"���"���Ա"
���ڣ�AI��Ȼ�����������������ܡ�
�⼸��ȸ�DeepMind����Kaggle����ʽ������һ����Ϊ"FACTS Grounding"�IJ���
FACTS��ʲô��˵���ˣ�����ר�Ų�AI"��û����һ�������غ�˵�˵�"��
���Է�����ֱ�ӣ���AIһ�ݳ��ĵ����32000��token�������������ĵ����ɻش�Ȼ������˵��ÿһ�仰�Dz��Ƕ��оݿɲ顢û�б��졣
����أ�
Ŀǰ��������ǿ��AIģ�ͣ�����������ȷ���ձ鿨��70%���¡�
�����ȸ��Լҵ�Geminiϵ�У�OpenAI��GPTϵ�У�û���κ�һ��ģ���ܱ�֤100%����ʵȷ�ԡ�
��ͺñȣ�������һ��Ч�ʼ��ߵ�Ա�����ɻ��ٶ��DZ��˵�ʮ��������ֻҪ���˵���ͷ��
�������Ա����30%�ĸ��ʻ�"�ſڿ���"����ͬ���д���������������ô��ͻ���Ϣ�Ź������
���������������������Ҫ��Ŀ��
AI��ȱ�ݣ�ǡǡ����ͨ�����Ļ��ᡣ
OpenAI�Լ�Ҳ˵�ˣ�GPT-5.2�Ķ�λ��"������ල��Э��רҵ����"��when paired with human oversight����
��ǰ�Ĵ�����ʲô��ִ���ߡ� �ϰ�˵д�����������д��˵���������������
�Ժ��������ΪAI���ϰ壬Ҫ�������Щ�����м�ֵ�ģ���Щ�¸ð��Ÿ��ĸ�AI�ɣ���������жϿ������ס���û�м�ֵ��
δ��ְ����������̭"��AI����"��һ������̭"��ͼ��AI��������"��

















