�����
�γ������й������ѧͳ����������о�Ժ��ʿ�о�����
̽��ѧ���ڵ�����֪ʶ���ƣ��ǿ�����Ա������ʷ��չ������δ���������Ҫ;��������ʹ�ҷ���������Journal of the American Statistical Association������һƪ���¡������¾۽�ͳ��ѧ���������һ��Э����������̬����ģ�ͣ�CDTM�������ڷ���ͳ��ѧ�����ڿ��ͻ������ģ���ʾͳ��ѧ�о���ȥ��ʮ����ݽ��켣�������ȵ㡣�о�ͬʱ���֣�һЩͳ���������������˹����ܵķ�չ���ܽ�ϣ�Ϊδ���Ĵ����о��ṩ�˲��ֲο������µ���ϸ��Ϣ���£�
Chenxuan He, Feifei Wang, Liping Zhu.��2026��. Emerging Knowledge Trend in Statistical Research��A Content-Based Analysis using Covariate-Assisted Dynamic Topic Model, Journal of the American Statistical Association.
https://doi.org/10.1080/01621459.2025.2602833
01
��������
ѧ�Ƶ��о���Ȥ�����ڲ����ݱ䣬��һ�仯�ܼ�����������������Լ�������ս��������������Щ�仯���ڿ�����Ա������Ҫ����Ϊ���ܹ�������������ѧ���ڵĹؼ���չ��̬���ڱ��о��У����Ǿ۽��ڷ�չ����ѧ��֮һ����ͳ��ѧ����ѧ����Դ��19����ĩ��20���ͳ����ڹ�ȥ��һ�������У�ͳ��ѧ�������������֧��������ά���ݷ�����ʱ�����з�������Ҷ˹�������ع鷽��������ѡ��ʵ������Լ��������Dz������۵ȡ�ͳ��ѧҲ������ѧ������ںϣ�����������ҽѧ��ѧ������ѧ������ѧ����������ͳ��ѧ�������˹����ܣ�AI��ʱ����Խ��Խ��������������ݿ�ѧ������ء���ˣ�̽��ͳ��ѧ�ķ�չ�����������о����������Ҫ���塣
̽��ijһѧ�Ƶ�����֪ʶ���Ƶ�һ�ַ����Ƿ�����ѧ�ƶ����ڿ������ġ����������¿��Է�ӳ���ܹ�ע�����Ծ���о����⣬��Щ����ͨ����ͬ��ʽ���������ϵ����ˣ������ڿ��ķ������Ŀ������о��ض�ѧ�Ƶ�����֪ʶ���ơ�������Щ���Ĵ���Ƿǽṹ�����ı����ݣ���˿��Բ���ר������ı��ھ�ļ������з�����Ϊ�ˣ�һ�ྭ�䷽��������ģ�ͣ�Topic Models������Ŀ���Ǵ��ĵ������з���DZ�����⡣����������ģ����DZ�ڵ��������䣨LDA, Blei et al., 2003����������ÿƪ�ĵ���ѭһ������ķֲ���ÿ����������ѭ�ʻ���ķֲ���������Щ���裬���Խ���������һ���������ģ�͡�������˵������ģ�͵ĺ������������ܹ���һ����ά�ҿɽ��͵�������ʾ�ĵ������ĵ�������ֲ����������������˹����ܵķ�չ��������ģ�ͣ�Neural Topic Models���ʹ�������ģ�ͣ�LLMs�����ı��ھ��б��Խ��Խ���С����� NTMs �ͻ��� LLMs �ķ������ı����ࡢ��Ϣ���������������б��ֳ�ɫ�������ǵ�ѵ��ͨ����Ҫ�������ݺͼ�����Դ��ͨ����ʾ��prompt���� LLMs Ӧ�����ض������ƺ���һ����㷽��������������ȱ��һ���������ԡ����⣬��Щ����ͨ����Ϊ�ı������ṩ�����ҿɽ��͵ı�ʾ�����֮�£���������ģ���ܹ��ṩ�ɽ����ҿ��������ı���ʾ���Ӷ�ʵ�ֽṹ���������ƶϡ� Lin et al.,��2025��Ҳ���֣���Ϊ LLMs �Ĵ�����ChatGPT �����Իع�ʹ�ô�ͳͳ�Ʒ����������⽨ģ����ˣ��ڱ��о��У�������Ȼ������������ģ����̽��ͳ��ѧ������֪ʶ���ƣ�ͬʱ���� LLMs �������������ڷ����ĸ������ۿɲμ���¼���ϡ�
Ϊ�˴��ѷ����������о�����֪ʶ���ƣ����ǵij�������������Э�������������˹ؼ����á�������Ϊ��������ͨ���ܶ�������Ӱ�죬�������ߺͷ������������������ȣ��漰ʵ��Ӧ�õ�����ͨ�������������ࣻ��ͬ��������и��Ե�ƫ�û��Ӷ�������������ͬ����ˣ��ڱ��о��У���������Э������Ϣ��̽��ͳ��ѧ��֪ʶ���ƣ������Э����������̬����ģ�ͣ�Covariate-assisted Dynamic Topic Model, CDTM����������ԣ��������ø�˹���̣�Gaussian process����ģ������ʱ���ڴʻ��ϵĶ�̬�ֲ�����ͨ�����ع��ܽ�Э�������ĵ�����ֲ���Ӱ������ģ�ͣ�ͬʱ����Э����ЧӦ��ʱ��仯������ͨ������ƶϣ�variational inference���� CDTM ���й��ƣ���������֤���������������¹�������һ���ԣ���ͨ��ģ���ĵ�չʾ�侭�����ܡ�������ǽ� CDTM Ӧ����ͳ��ѧ�����ڿ�����ػ�������ģ���̽����ȥ��ʮ��ͳ��ѧ֪ʶ���ݽ����ơ�������˵������ϣ���ش��������⣺
��Q1���ڹ�ȥ����ʮ���ͳ���о��еĹؼ�����ͷ����ϵĽ���������ݱ�ģ�
��Q2������˹����ܵ�����ͳ��ѧ��������η�չ�ģ���ʷ�о��Ľ�չ���������ݿ�ѧ���˹�����֮����������������ϵ��
��Q3��Э�������緢�����ڿ������ߵĺ���ģʽ����ͳ���о����Ʒ����������������ã�
02
��������������
2.1 �����ռ�������ͳ��ѧ��AI�Ľ���ش�
�����ռ���ͳ��ѧ�Ĵ��ڿ��Լ���ͳ��ѧ����Խϸߵ�����AI��������ݡ����У�ѡȡ��ͳ��ѧ�Ĵ��ڿ����� Journal of the American Statistical Association��JASA����Annals of Statistics��AOS����Journal of the Royal Statistical Society Series B��JRSSB����Biometrika��BKA����ѡȡ��������ͳ��ѧ����Ըߵ�AI�������International Conference on Artificial Intelligence and Statistics��AISTATS����International Conference on Machine Learning��ICML����Conference on Neural Information Processing Systems��NeurIPS����
������ԣ������ռ�����1980����2024�귢�����ĸ��ڿ��ϵ����£��Լ�2014����2024�귢�������������ϵ����¡����ڿ�/����������������£�
��1���ռ��������������ڿ����Ϊ1980�C2024���������Ϊ2014�C2024��

�����������鲻������ͳ��������ģ����д��������ѧϰ��AI��������£��������ȶԻ������Ľ���Ԥɸѡ��Ŀ���Ǵ���������������ѡ����ͳ��ѧ��ضȸߵ����¡����Dz�ȡ���µ�ɸѡ��������1��ʹ�� BERT��Devlin, Chang, Lee & Toutanova 2019�����ڿ��ͻ������µı���ת��Ϊ������ʾ��ʽ����2�������ĸ�ͳ��ѧ�ڿ������µ�ƽ����������Ϊͳ��ѧ�о��Ĵ�����������3������ÿƪ�������ĵ��������ı��ڿ���ƽ������֮����������ƶȡ����Ƿ��֣���ͬ����������ͳ���ڿ����ĵ��������ƶȸ�����ͬ��ǰ30%�ķ�λ�����¶�Ӧ������������ˣ������ڷ�����ѡ��������ص�Լ30%�Ļ������������о������С����У� NeurIPS ���� 4285 ƪ��ռ�������ĵ�Լ31%����ICML ���� 2750 ƪ��ռ�������ĵ�Լ26%����AISTATS ���� 1448 ƪ��ռ�������ĵ�Լ41%�����������ַ���ɸѡ���������ݼȸ�����ͳ��ѧ�ĺ����ڿ�����������AI������ͳ�ƽ����ǰ�سɹ���Ϊȫ�����ͳ��ѧ���ݱ��ṩ�˼�ʵ������
2.2 ���ķ�����������
���������������ķ��������ı仯����ͼ1������2010��������������ͳ��ѧ��ص�AI������������ָ����������ͬ���ĸ�ͳ���ڿ��ij���������������ȶ�����һ�ؼ���������AI������ͳ���ڿ���ͬ�ı༭���ߣ�������������Ľ�����ͨ��ά���� 20%�C30% ֮�䡣���֮�£�ͳ��ѧ�ڿ�������ͼ����ÿ����Թ̶��ķ�����������ʹ��������Ͷ�������ӵ�����±�������ϸ����磬JRSSB �� 1990 ���Լ�յ� 200 ƪͶ�壬������ԼΪ 25%��Kent & Smith 1991������ 2020 �꣬Ͷ������������Լ 600 ƪ�������������½���Լ 8%��Delaigle & Wood 2021������һ���Ʋ��� JRSSB ����, JASA �ڽ����걨��Ľ�����ҲԼΪ 10%��American Statistical Association 2022������������ѧ������ԽϸߵĽ�������ȣ�ͳ��ѧ�ڿ��ϵ͵Ľ������ѵ���һ���������Ե����ƣ���Խ��Խ�����Ҫ�о��ɹ�ת���ڼ������ѧ�����Ϸ�����
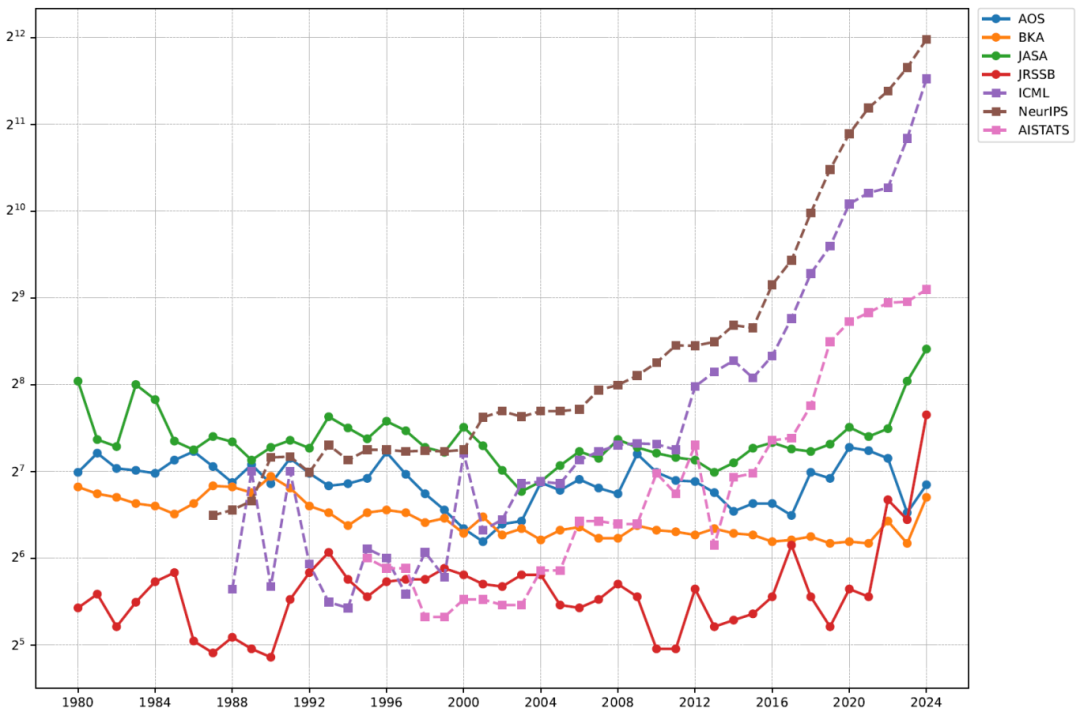
ͼ1�����ڿ�/�������ķ������仯��1980�C2024�������߶ȣ�
2.3 Ӱ�����ӱ仯
ͼ2��ʾ��Clarivate�����Ψ����������ĸ�ͳ���ڿ���Ӱ�����ӡ������ʾ��Ӱ��������ʱ���������������������Ƴ����ձ������켣��������Щ�ڿ���ѧ�����Ӱ�������Ͽɶ������ӡ�����ֵ��ע����ǣ�Clarivate�ṩ��Ӱ������ֻ�����ڿ�֮��Ļ������á�AI�����û��Ӱ�����ӣ����ǵ�����Ҳ������������ڿ���Ӱ�����ӵļ��㡣
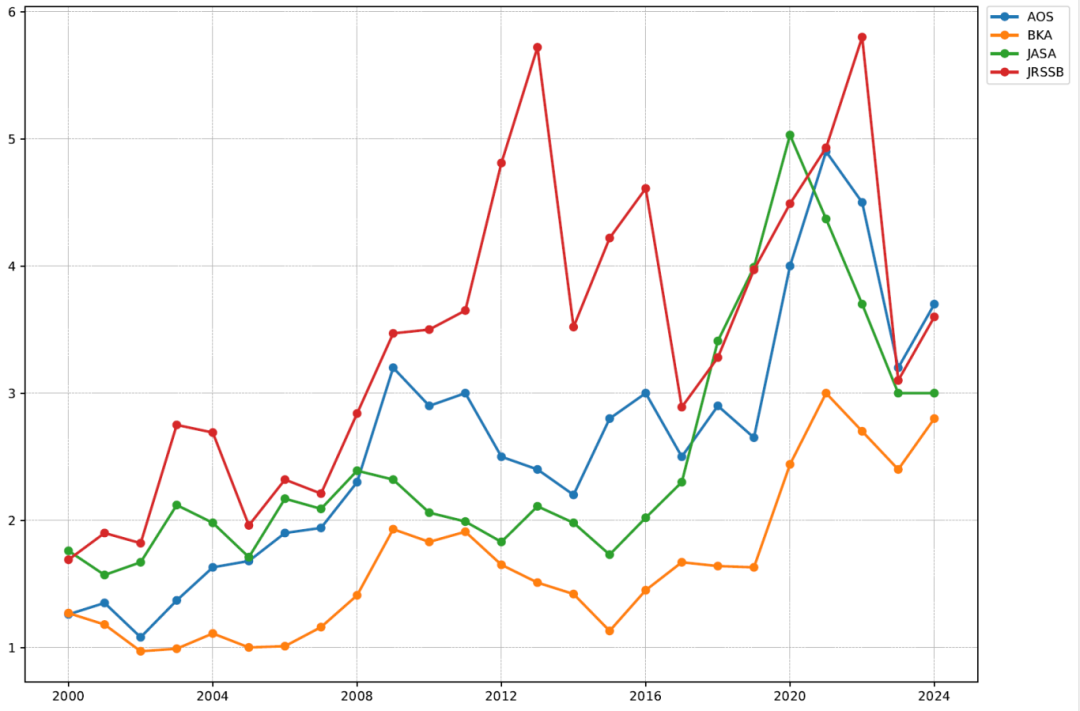
ͼ2��ͳ��ѧ�Ĵ��ڿ�Ӱ�����ӱ仯��2000�C2024��
2.4 �߱������ķ���
Nature��2025�귢����һƪ���ķ�����21����ȫ��ѧ����߱������ĵ������Pearson, Ledford, Hutson & Van Noorden 2025�����ڴ������£�����Ҳ����ͳ��ѧ�Ĵ��ڿ������������и߱������ĵ����������Google Scholar���������ݣ���������������ʱ�ڵĸ������ģ����ճ�ͳ��ѧ���ݱ�켣��
��һ�Σ�1979��-2014�ꡪ�������뷽���Ļƽ����
�����ʱ�ڣ�ͳ��ѧ����˴Ӿ����������ִ�������ת�͡������ҳ������ʱ����Google Scholar���ô�������10000�ε�20ƪ���ģ������2�����У���������ߵ�Ϊ Benjamini & Hochber��1995���������ٷ����ʣ�FDR�����Ʒ������ۼ����ó���12��Σ����4000+���á���ƪ���Ľ���˶��ؼ�������еĺ������⣬�������Ǹ�����ıض����ס�
��2��1979�C2014��ͳ��ѧ�Ĵ��ڿ����������£�Google Scholarͳ�ƽ�ֹʱ��Ϊ2025��10��25�գ��������������ģ������������������У�
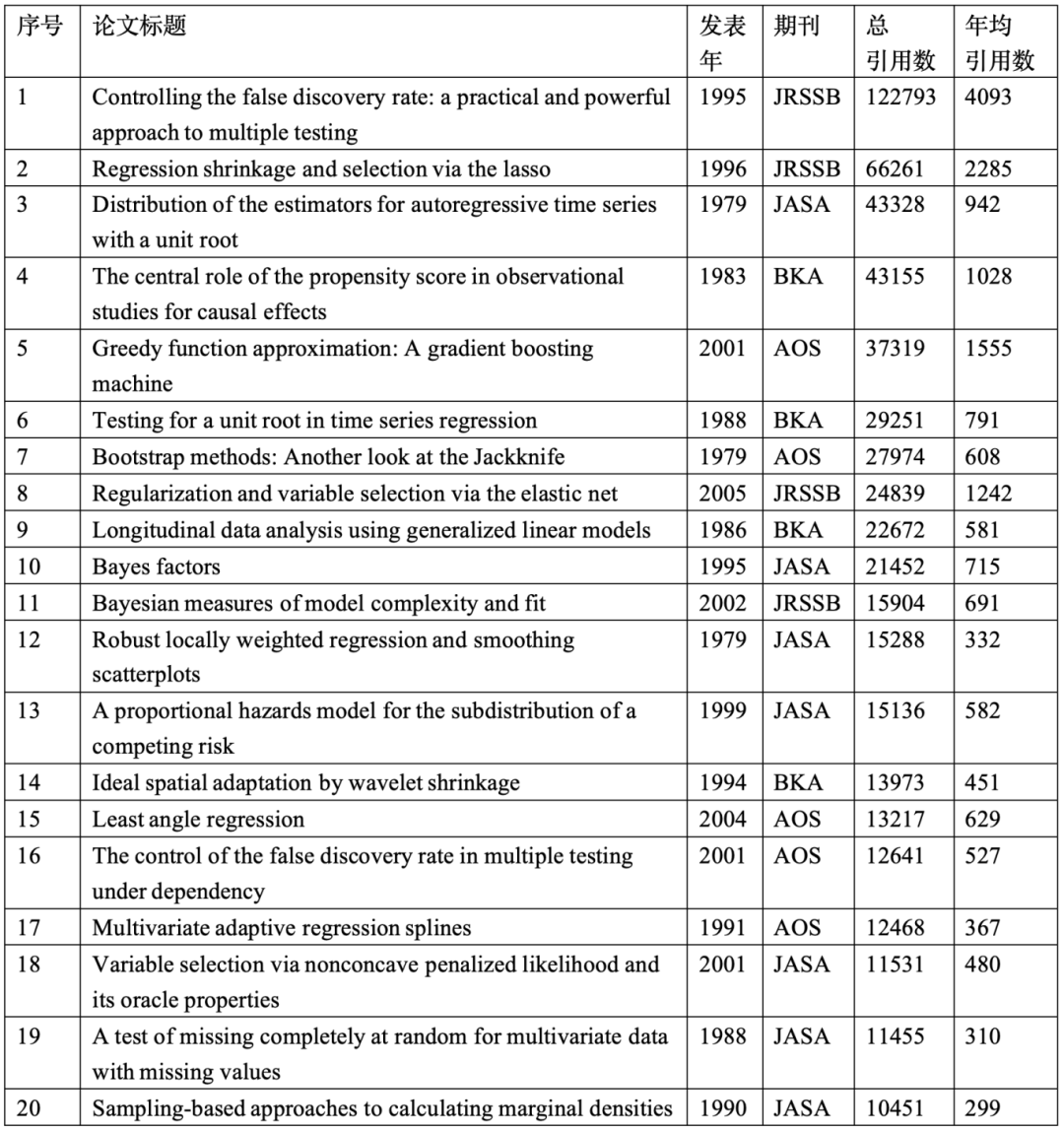
���ʱ����ӿ�����ڶ�����Է������£����磺
➢ ϡ��ͳ�ƺ�ά���ݷ�����ط���������
�� LASSO��Tibshirani 1996, JRSSB������6�������
�� SCAD��Fan & Li 2001, JASA������1�������
�� Elastic net����������Zou & Hastie 2005, JRSSB������2�������
➢ Bootstrap��Efron 1979, AOS��2.8�����á����ز�����������̱�����ͳ���ƶϲ��������ϸ�ķֲ�����
➢ ����ƶ�������������֣�Rosenbaum & Rubin 1983, BKA������4������
➢ �����ɷ������ؿ���MCMC��Gelfand & Smith 1990, JASA������1�����ã��DZ�Ҷ˹����ĸ�����ͻ��
���ʱ�����ص��ǣ���Щ���ĵ춨���ִ�ͳ��ѧ�����ۺͼ����������Ӱ������Խ���ҽѧ�����á����ڵȶ��ѧ�ƣ���Ϊ���������ݷ����ı����ߡ�
�ڶ��Σ�2015-����AI�ںϣ������۴��µ���Ӧ��ս
��������ݺ�AIʱ����ͳ��ѧ���о�����Ҳ������һ���仯����ͳ�Ƹ߱�������ʱ��������ݽϽ���Ϊ�˸���ƽ�رȽϲ�ͬ��ݵ����ģ�����ʹ�á�������ô�������Ϊָ�꣬�õ���3���������ǰ10�����ġ�
��3��2015�C2024��ͳ��ѧ�Ĵ��ڿ����������£�Google Scholarͳ�ƽ�ֹʱ��Ϊ2025��10��25�գ��������������ģ�������������������У�
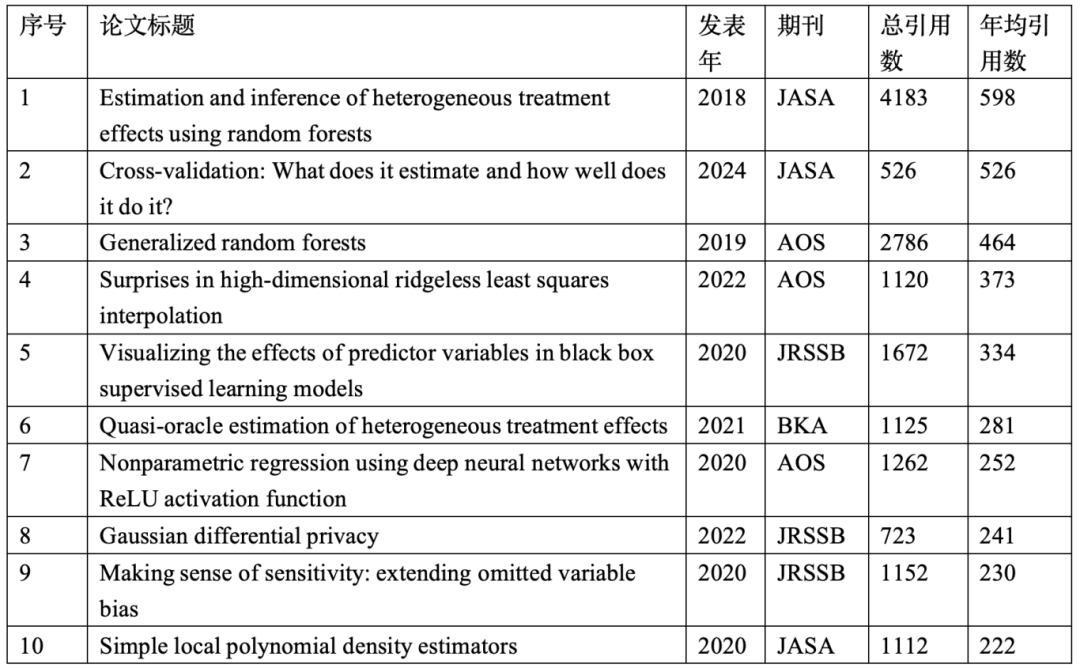
���Ƿ��֣����ڸ������ij��ֳ����������ƣ�
����1���ɽ���AI��Ϊ��������
✓ ����ģ�Ϳ��ӻ���Apley & Zhu 2020, JRSSB�������300+�����á���Ϊ����ģ���ṩֱ�۵Ľ�����
✓ ������������ۣ�Schmidt-Hieber 2020, AOS�������200+�����á���Ϊ���ѧϰ�ṩ�ϸ�ķDz�������
✓ ��ά��������ridgeless����С���ˣ�Hastie, Montanari, Rosset & Tibshirani 2022, AOS�������200+���á���Ϊ��������˫�½�����double descent���������������������½���������ṩ����
✓ ʹ�úں�ģ�ͽ������ƶϵ����⣨Wager & Athey 2018��Athey, Tibshirani & Wager 2019��Nie & Wager 2021��
����2�����䷽�����ִ���Ӧ�û����
✓ ������֤���ۣ�Bates, Hastie & Tibshirani 2024, JASA�������500+�����á�������������һ���䷽�����ش�������������ʲô��Ч����Σ���
✓ ���ھֲ�����ʽ�ķDz����ܶȹ��ƣ�Cattaneo, Jansson & Ma 2020, JASA�������200+������
✓ ���ɭ�֣�Wager & Athey 2018, JASA�������500+�����á��������ɭ��������ƶϽ�ϣ����������Դ���ЧӦ
✓ �������ɭ�֣�Athey, Tibshirani & Wager 2019, AOS�������400+�����á�����һ���ƹ����ɭ�ֿ��
✓ ����ƶ�����������Ĺ��Ʒ�����Nie & Wager 2021, BKA�������200+����
����3��AIʱ���£���˽���⡢�ֲ�ʽѧϰ�����������
✓ ��˹�����˽��Dong, Roth & Su 2022, JRSSB�������200+�����á�����������˽�����������Ҫ��չ
✓ �ֲ�ʽѧϰ��Jordan, Lee & Yang 2019, JASA�������100+���ã���δ����Top 10������������Ѹ�١�����ӳ���ģ���ݴ�������ʵ����
03
CDTM��������
Ϊ��ϵͳ������ͳ��ѧ���ݱ䣬���������Э���������Ķ�̬����ģ�ͣ�Covariate-Assisted Dynamic Topic Model, CDTM����������ÿƪ�����Զ����ϡ������ǩ����Ȼ������Щ����ǩ����40��������仯����ģ�͵ĺ���˼���ǣ���ÿƪ���Ŀ���������⣨�����ȣ��Ļ�ϣ��������ֲ��������ȿ��Ա�Э����xӰ�죻ÿ����������һ���ʷֲ������������� �£����ƣ�����ʷֲ�������ʱ������ݱ仯��CDTM��ģ�Ϳ��ͼ�����ͼ3��
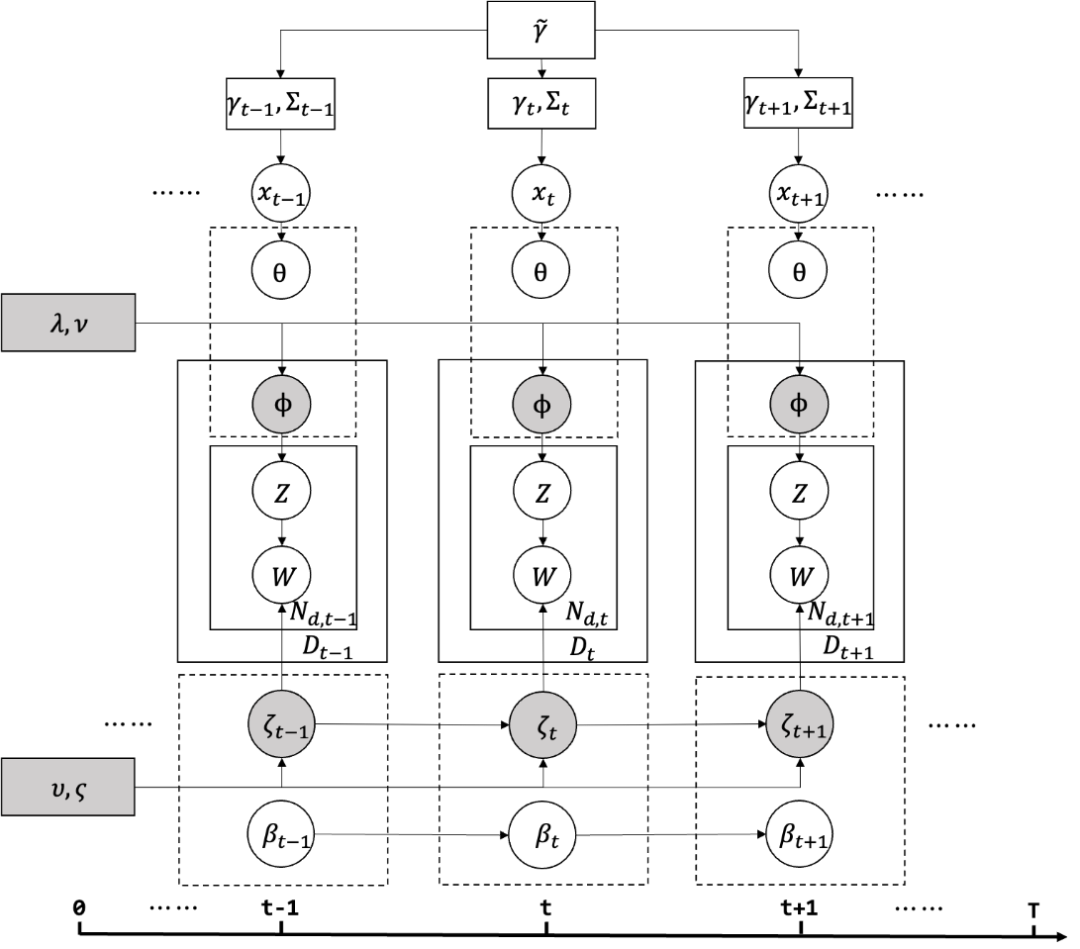
ͼ3��Э���������Ķ�̬����ģ��ʾ��ͼ
ͨ������ƶϵķ�����ȡÿ���ĵ���DZ������ֲ��Լ�ÿ�������DZ�ڴʷֲ�������Щ������ʱ���ϵ��ݱ��Լ���ͬЭ���������ڿ������顢�������ȣ��������Ӱ�졣��ģ�����ݺ���ʵ�����ϣ�CDTM����������ָ����������ڶ�̬����ģ��DTM��Blei & Lafferty 2006�����ṹ����ģ�� STM ��Roberts, Stewart & Airoldi 2016���Ⱦ��䷽������������ϸ������ο�����ԭ�ġ�
04
ʵ֤����
4.1 CDTM��ģ
���ǽ��������Э����������̬����ģ�ͣ�CDTM��Ӧ����ͳ��ѧ�������ݼ���Ϊ�̻�������ʱ��Ķ�̬�仯�����Ǹ��ݷ�����ݽ����ݼ�����Ϊ 45 ��ʱ��Ƭ������ 1980��2024 �ꡣ���ǿ�������Э�����������7����𣩡�����������������������
�ڽ�ģ֮ǰ��Ҫȷ���������K��Ϊ�ˣ����ǿ���һϵ����������ѡ��Ȼ��������ֳ�������ָ�����ģ��������ǰ����ָ��Ϊһ���Ե÷֣�coherence score, CS����һ���㻥��Ϣ��normalized pointwise mutual information, NPMI�������ں���ÿ�������и�Ƶ�ʵ�����һ���ԡ�CS �� NPMI ֵԽ�ߣ����������ڴʻ���������Խ��ء��ɽ�����Խǿ��������ָ��Ϊ�Ľ������� Jaccard ָ����refined diversity Jaccard index, RDJ�������ں�����ͬ����֮��Ķ����ԣ������������ʻ��ص��̶ȡ�RDJ ֵԽ�ͣ�˵���������ֶ�Խ�ߡ�������Խ�͡���ͬ�������µ�CDTM�ı��ּ���3. ���������CS��NPMI��K=8ʱ�ﵽ���ֵ����RDJ��K=10ʱȡ����Сֵ���������K=8���бʸĽ����ۺ�����Ȩ�⣬��������ѡ��K=8��Ϊ CDTM ��������������
�� 4����ͬ�������µ���������ָ�ꡣ���ϼ�ͷ��ʾ��ָ����ֵԽ��Խ�ã����¼�ͷ��ʾ��ָ����ֵԽСԽ�á��Ӵֱ�ʾ���Ž��

���ǽ�һ���� CDTM �����ֶԱȷ��������˱Ƚϣ���1����̬����ģ�ͣ�DTM��Blei & Lafferty 2006������2���ṹ����ģ�ͣ�STM��Roberts et al. 2016������3����̬��������ģ�ͣ�DLTM��Glynn et al. 2019������4��BERTopic ģ�ͣ�Grootendorst 2022������5��FASTopic ģ�ͣ�Wu et al. 2024������6��ProdLDA ģ�ͣ�Srivastava & Sutton 2017�����Լ���7����̬Ƕ������ģ�ͣ�DETM��Dieng et al. 2019�������У�DTM��STM �� DLTM ���ڱ�Ҷ˹����ģ�ͣ�DETM Ϊ��̬������ģ�ͣ�BERTopic �� FASTopic Ϊ���� Transformer ��������ģ�ͣ�ProdLDA ���ǻ��ڱ���Ա�������VAE����������ģ�͡����� BERTopic ��֧���û���ʽָ��������������ͨ��������ز���ʹ�����K=9�����⣬�Ի���� CDTM ��K=8��������Ϊ�ɱȵĽ��������ģ�;�����ʵ���ݼ������У������������̶�Ϊ $K=8$���� 5 ���ܵĽ��������CDTM ����������ָ���Ͼ����ֳ����ŵ����ܡ�CDTM ��������������ϸ�Ƚϼ����IJ�����ϡ�
�� 5����ͬģ�͵���������ָ�ꡣ���ϼ�ͷ��ʾ��ָ����ֵԽ��Խ�ã����¼�ͷ��ʾ��ָ����ֵԽСԽ�á��Ӵֱ�ʾ���Ž��

4.2 ���⺬��
���������ص��עCDTM��ȡ�������⺬�塣ģ��һ���ھ��8�����⣬���Ը���ÿ�����������дʵĸ��ʷֲ��Լ����ֵĸ߸��ʴʶ����⺬������ܽᡣ���ͬʱ�����ǻ�����������ģ�ͣ�LLMs���������ܽ������ĺ��塣������ԣ������� ChatGPT ����������⣺��Here are several key words from a series of articles in statistics. Can you help me summarize the topic of these articles in a few concise words?�� ����������Ļش���Ϊ������ܽ�������ÿ������ĺ����ܽ����¡�
✓ ����1���㷨���Ż���Algorithm and Optimization��
➢ �����Թؼ��ʣ�EM�㷨��EM algorithm��������ݶȣ�stochastic gradient�����Ż���convex optimization����ԭ��ż��primal dual����ǿ�ԣ�strongly convex��������ƽ���stochastic approximation��
➢ �������ģ�
�� Լ�������ɷ���߹��̵Ľ����������Ӷȣ�Vaswani, Yang & Szepesvari 2022, NeurIPS��
�� һ�����ȸ��ʳ���������Saxena, Singh & Srivastava 1986, BKA��
➢ ��������������ͳ�Ƽ���ĺ����㷨���Ӿ����EM�㷨���ִ�������Ż�������
✓ ����2����Ҷ˹ͳ�ƣ�Bayesian Statistics��
➢ �����Թؼ��ʣ����飨prior�������飨posterior������ȷ����������uncertainty quantification�������ЧӦ��random effect������˹���̻ع飨Gaussian process regression����MCMC
➢ �������ģ�
�� ��Ҷ˹Ԥ����Ϣ��Ando 2007, BKA��
�� �������Ժͼ��Զ��ģ�͵�ͶӰԤ��������Catalina, B��rkner & Vehtari 2022, AISTATS��
➢ ����������Ҷ˹�ƶϼ����ڲ��ģ�͡���ȷ���������е�Ӧ�á�
✓ ����3�����ѧϰ��Deep Learning��
➢ �����Թؼ��ʣ� �����磨neural network�����ܹ���architecture������ʾѧϰ��representation����Transformer��Ǩ��ѧϰ��transfer learning����Ԫѧϰ��meta learning��
➢ �������ģ�
�� ͼ��ʾѧϰ�ķ�����ɢģ�ͣ�Yang, Yang, Zhou & Sun 2023, NeurIPS��
�� ������ɷ�����Coupled generation����Dai, Shen & Wong 2022, JASA��
➢ �������� ͳ��ѧ�����ѧϰ�������о��ͷ������£����ǽ�ʮ�������������⡣
✓ ����4������ͳ�ƣ�Biostatistics��
➢ �����Թؼ��ʣ� ������measurement������Ԥ��intervention�������ٰ���breast cancer�����н������mediator���������ʣ�mortality�������������survival analysis��
➢ �������ģ�
�� GWAS�е��Ŵ�����Թ��ƣ�Zhao & Zhu 2022, JASA��
�� ���Խṹ���ģ�͵������Է�����Cinelli et al. 2019, ICML��
➢ �������� ����ҽѧӦ���е�ͳ�Ʒ�������������������ٴ����顢������ѧ�ȡ�
✓ ����5���Dz���ͳ�ƣ�Nonparametric Statistics��
➢ �����Թؼ��ʣ� �ܶȹ��ƣ�density�����˷�����kernel���������ٶȣ�rate of convergence��������ѡ��bandwidth selection�������Σ�manifold��������ϣ�����ؿռ䣨RKHS����oracle����ʽ��oracle inequality��
➢ �������ģ�
�� Wasserstein GAN�ļ�С���������ԣ�St��phanovitch, Aamari & Levrard 2024, AOS��
�� R��nyiɢ�ȵķDz������ƣ�Krishnamurthy, Kandasamy, Poczos & Wasserman 2014, ICML��
➢ �������� ���������������ͳ���ƶϷ����������Խ�ǿ��
✓ ����6���ع������Regression��
➢ �����Թؼ��ʣ� Lasso����λ���ع飨quantile regression����������С���ˣ�generalized least square������ֽ�ά��sufficient dimension reduction��
➢ �������ģ�
�� ��Э�����췽������ģ�͵��ƶϣ�Cattaneo, Jansson & Newey 2018, JASA��
�� ������ֵ���ֺ������Ƶĸ�ά�Ǹ�˹��ָ��ģ�ͣ�Yang, Balasubramanian & Liu 2017, ICML��
➢ �������� ����ع鷽�����Ӿ������Իع鵽��άϡ��ع顣
✓ ����7���ලѧϰ��Unsupervised Learning��
➢ �����Թؼ��ʣ� ���ࣨcluster�����ݶ�����gradient flow�����ַ��̣�differential equation����������sampling��������Ա�������variational auto-encoders��VAE��
➢ �������ģ�
�� ����VAE��ʵ���ɽ����ԣ�Kong & Chaudhuri 2021, NeurIPS��
�� �������ɷ�ģ�͵��ӿռ���ƺ�Ԥ�ⷽ����Andersson & Ryd��n 2009, AOS��
➢ �������� �ޱ�ǩ���ݵ�ģʽ���֣��������ࡢ��ά������ѧϰ�ȡ�
✓ ����8���������⣨Others��
➢ �����Թؼ��ʣ� ���ؼ��飨multiple testing����ʵ����ƣ�experimental design��������ɸѡ��feature screening������ֵ���ۣ�extreme value theory�������Ⱦ�����ƣ�precision matrix estimation����
➢ �������� �����ͳͳ�Ʒ�֧�ļ��ϡ�
ֵ��ע����ǣ�һƪ����ͨ������רע�ڵ�һ���⣬���Ǻ��Ƕ������⣬��һ����ÿ���ĵ���������� �� �������֡����磬һЩʹ����������зDz����ع顢�����Dz����������ʵ����ģ���Ҫ��������3�����ѧϰ��������5���Dz���ͳ�ƣ�������6���ع����������Schmidt-Hieber��2020���� Jiao, Shen, Lin & Huang��2023����
������õ������У����ǿ��Թ۲쵽�����˹�����ʱ������֮�ʣ�ͳ��ѧԽ��Խ��ע���˹�����������ص����⡣���磬����3�����ѧϰ����Ϊ�ִ����ݿ�ѧ�ĺ���Ҫ�أ��ѳ�Ϊͳ��ѧ��һ�����˵��о�����ͬʱ������ͳ��ѧ�еľ������������ݿ�ѧ�������������磬����6���ع����������Ϊͳ��ѧ�еĻ��������������ݿ�ѧ��Ԥ�⽨ģ�еõ��˹㷺Ӧ�á����⣬����2����Ҷ˹ͳ��ѧ�����ִ�����ѧϰ�����еĸ����ƶ�������أ��ر��������ѧϰ��ǿ��ѧϰ�С���ˣ����ǿ��Կ����������ͳ�����������ִ����ݿ�ѧ��������ս�����Ϸ�չ���ƶ��˸�������Ĵ��ºͽ�����
4.3 �����ȶȱ仯
ͨ������ÿ�������ڲ�ͬʱ�ڵ�ռ�ȣ������������ȶȣ�������Щ��Ȥ�ķ��֡������������ĸ�����Ϊ������˵����
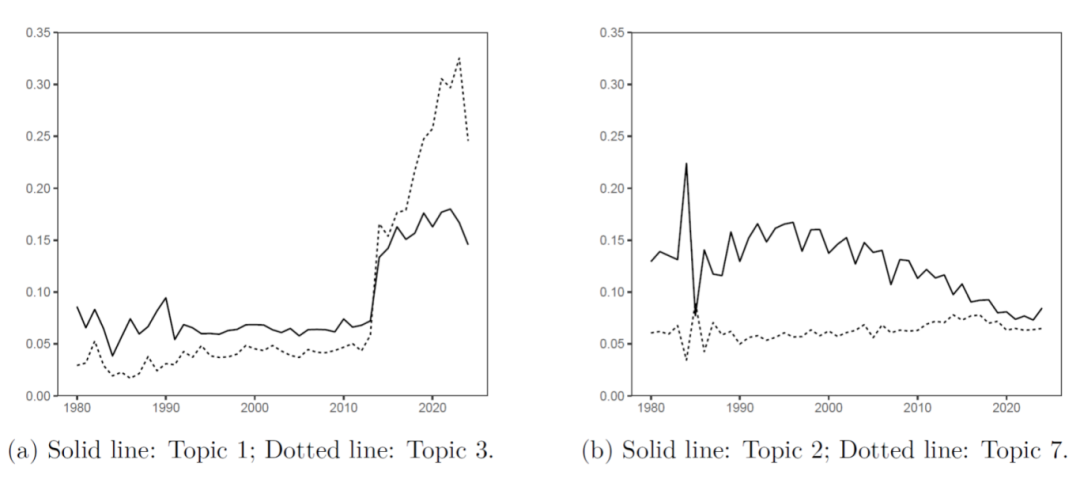
ͼ4����a������3�����ѧϰ��ʵ�ߣ�������1���㷨���Ż������ߣ�����b������2����Ҷ˹ͳ�ƣ�ʵ�ߣ�������7���ලѧϰ�����ߣ�
🚀 ����ʽ����������3�����ѧϰ���⣩
���ѧϰ������2010��֮ǰ������������ͳ���ڿ��У���������AI�������ĺ�2010�꿪ʼ������ռ�ȳ��ֱ���ʽ��������2020��������ѧϰ�ѳ�Ϊͳ��ѧ���۵ĺ�������֮һ���ⷴӳ��ͳ��ѧ��AIʱ���Ļ�����Ӧ�������DZ������ܣ���������Ϊ���ѧϰ�ṩ���ۻ����Ϳɽ����Թ��ߡ�
📈 ��������������1���㷨���Ż���
�㷨���Ż�������ͳ���ڿ���һֱ�����ȶ����ڣ����ڼ���������ĺ�ͬ������������������˵������Ч�ʺ��Ż��㷨���ִ�ͳ���е���Ҫ�����վ�����
📉 ����½�������2����Ҷ˹ͳ�ƣ�
��Ȥ���ǣ���Ҷ˹ͳ����Ϊһ���������⣬��ռ���ڹ�ȥ40����ֻ����½����ơ��Ⲣ����ζ�ű�Ҷ˹��������Ҫ�ˣ����Ƿ�ӳ��ͳ��ѧ�о�����Ķ�Ԫ�������������⣨�����ѧϰ��������������о�ע������
🔃 �ȶ���չ������7���ලѧϰ��
�ලѧϰ����������ʱ�ڱ�������ȶ���ռ�ȣ���ʾ������Ϊ�����о�����ij־���������
4.4 ���⺬��仯
���ǽ������������⺬��ı仯��Ҳ����ÿ�������¸߸��ʴʵĶ�̬�仯�������ԡ��㷨���Ż���������1���͡��Dz���ͳ�ơ�������5��Ϊ����չʾ�������ڲ�ͬʱ��εĸ߸��ʴʡ�ͼ5չʾ������������ʱ��㣨1980 �ꡢ1990 �ꡢ2000 �ꡢ2010 �ꡢ2017 ��� 2024 �꣩�ĸ߸��ʴʻ������
��������1���㷨���Ż���������ʹ�õĴʻ�����㷨��Algorithm����������Technique���Լ���ظ������EM �㷨��EM Algorithm���� 1980 ���� 2000 ���ڼ�ռ��������λ��Ȼ������ 2010����� 2020 �����������������ݶȣ�Stochastic gradient��������ѧϰ��machine learning���Ͳ��ԣ�Policy�������Ĵʻ�仯���������ѧϰ��ǿ��ѧϰ�Ľ������Ǻϡ��������ʱ�ڣ��Ż���Ϊ��һ���������⣬��ӳ��ͳ���㷨�����渴�����Լ����Ƚ��Ż����Ե�����
������5���Dz���ͳ�ƣ��У�����Dz�����nonparametric�����������ʣ�rate of convergence�������������ر�������Ծ���Dz������۵IJ��ء��� 20 ���� 80 ����� 90 ����ڼ䣬���������Ȼ��maximum likelihood����������bandwidth���ͽ�����֤��cross validation�������������봫ͳ�ķDz������������ϡ��� 2000 �꣬С����wavelet��һ�ʳ�Ϊ�ؼ��������ʮ���������ֳ����ά������high dimensional����ת�����ơ�ֵ��ע����ǣ�Wasserstein���루Wasserstein distance���� 2024 ����ͻ���������������ѧϰ�е�����ģ���Լ��ֲ��ع��������ء�
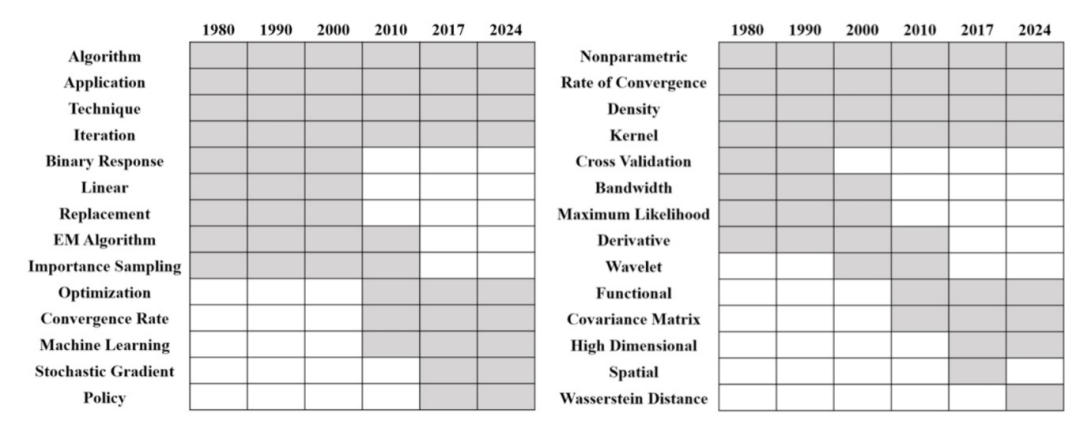
ͼ5������1���㷨���Ż���������5���Dz���ͳ�ƣ��ң���ͬʱ�θ�Ƶ�ʣ���ɫΪ��Ƶ�ʣ�
���ڵ�һ�ڵ����⣨Q1�������ǿ��Եõ����ۣ�ͳ��ѧ������ݱ���ֳ����Ե����ƣ����Ӵ�ͳ����������ת���˼����ܼ��ͺ��������������������ѧϰ��������3��������������Խ��Խ��Ҫ���������� 2010 ��֮����Ҷ˹ͳ�ơ�������2�������Ĵ�ͳ�������������Ե��½���ͼ5�еĴʻ��ݱ��һ��֤ʵ����һת�䣬ͻ���˾������ﱻ����ѧϰ���Ż�����ĸ�����ȡ����
���ڵ�һ�ڵ����⣨Q2�������ǿ��Եõ����ۣ������˹����ܵ�����ͳ��ѧ�����������ı仯����һ�㲻�������ڽ����������ѧϰ��������3���͡��㷨���Ż���������1��������Ĺ㷺Ӧ�ã��������ھ���������ݱ��ϡ����磬���Dz���ͳ�ơ�������5�������˹���������ת�ƣ���Ϊͳ���о�Խ��Խ���������˵��˹����ܸ�����зDz����������������������ReLU������Ļع�����������ģ���е�Wasserstein���������ȡ���Щ���������ִ����ݿ�ѧ��ͳ���о�������ںϡ�
4.5 �ڿ�ƫ�õIJ���
����CDTM��ģ�ͽ�������Ƿ��ֲ�ͬ������������ƫ��Ҳ�����������죬һЩ��Ҫ�Ľ������£�
➢ AOS�� ��ƫ��������ǿ�����⣬��Dz���ͳ�ƣ�����5��
➢ JASA�� ����עӦ�õ�������⣬��ع����������6��������ͳ�ƣ�����4��
➢ AI���飨NeurIPS/ICML/AISTATS���� �������ʵ������㷨�Ż�������1�������ѧϰ������3��
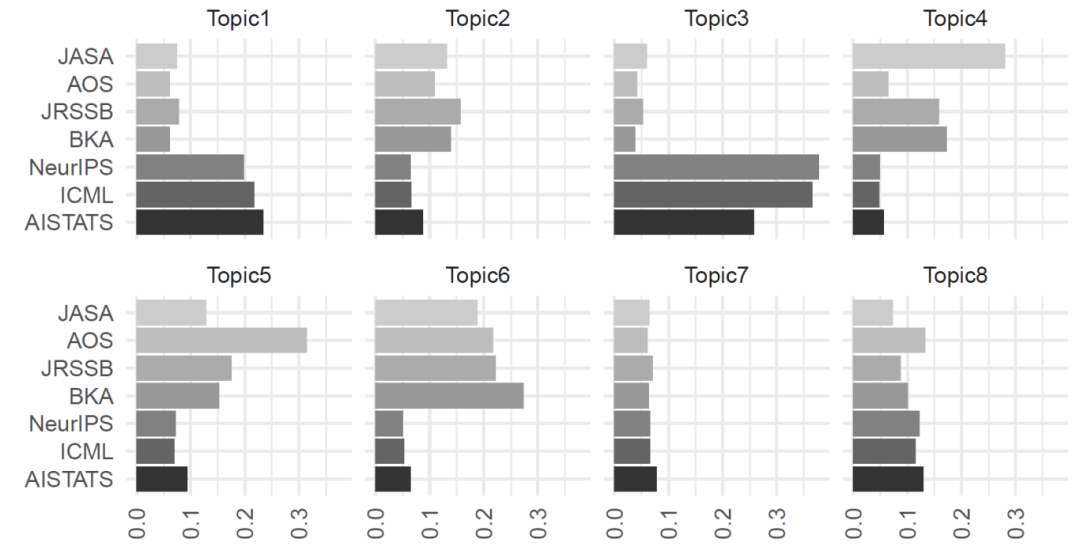
ͼ6���������¸����ڿ�/�����ռ�ȣ�����1���㷨���Ż�������2����Ҷ˹ͳ�ƣ�����3�����ѧϰ������4������ͳ�ƣ�����5���Dz���ͳ�ƣ�����6���ع����������7���ලѧϰ������8���������⣩
���ڵ�һ�ڵ����⣨Q3�������ǿ��Եõ����ۣ�Э�����������о����Ʒ������Źؼ����á��������ڿ����о���������г̶������ش�Ӱ�죬����������ڼ���������⣬���ڿ�����������ۻ��������⣬���ߵ��������������ѧϰ��Ӧ��������������أ�����3�����ⷴӳ���ִ����ݿ�ѧ�о���Э�����ʡ�
05
�ܽ�
�Ӹ������ĵı仯�������ݱ䣬һ���������ź��ǣ�ͳ��ѧ���ھ����ӡ����������ۡ�������AI���衱����ʷ��ת�͡� ͳ��ѧ������Ϊ���ѧϰ�ṩ����֧�ţ��������Է����������磩�����ڿɽ����ԡ�����ƶϡ���˽�����ȷ�������AI�ķ�չ��������Lin et al.��2025���Ĺ۵㣺ͳ��ѧ����Ҫ��ӦAI�����𣬸�Ҫ��������AI�ķ�չ�����ṩ���Ͻ��ԡ��ɽ����ԺͲ�ȷ������������Щ���Ǻ���ģ������Ҫ�ġ�ͨ��������Щ�������ƣ������ܹ����õ�Ԥ��ͳ��ѧ�о���δ����չ�����ٽ���ѧ�ƺ�������Ӧ�Բ���ӿ�ֵ�����ս��
ע������ο���������ԭ�ġ�

















