
大语言模型知识冲突的综述
2024-07-04,阅读:246

一、结论写在前面
论文来自:清华大学,西湖大学,香港中文大学论文标题:Knowledge Conflicts for LLMs: A Survey论文链接:https://arxiv.org/pdf/2403.08319
论文广泛探讨了知识冲突,阐明了其分类、成因、LLMs对这些冲突的响应方式及可能的解决方案,强调了在融合上下文知识和参数知识时所遇到的复杂挑战。论文的研究重点是三类知识冲突:上下文-记忆冲突、跨上下文冲突和内存内冲突。这些冲突显著影响LLMs的可信度和性能,特别是在现实世界应用中,噪声和错误信息普遍存在。通过分类这些冲突,探究其成因,检查LLMs在这些冲突下的行为,并回顾现有解决方案,论文旨在为提高LLMs的鲁棒性提供策略,从而成为推动这一不断发展领域研究的重要资源。
二、论文的简单介绍
2.1 论文的背景
将上下文知识集成到大型语言模型(LLMs)中能使它们跟上当前事件,并生成更准确的响应,但由于丰富的知识来源,也存在冲突的风险。上下文与模型参数化知识之间的差异被称为知识冲突。
论文将知识冲突分为三种不同类型,如图1所示。如图1中的例子所示,当使用LLM回答用户问题时,用户可能为LLM提供补充提示,而LLM也利用搜索引擎从网络上收集相关文档以增强其知识。用户提示、对话历史和检索到的文档的组合构成了上下文知识(context)。上下文知识可能与LLM参数中包含的参数化知识(memory)发生冲突,论文称之为上下文-记忆冲突(CM)。在现实场景中,外部文档可能充满噪音甚至是故意制造的错误信息,这使得它们难以准确处理和响应。论文将各种上下文知识之间的冲突称为上下文间冲突(IC)。为了减少回答中的不确定性,用户可能以不同形式提出问题。因此,LLM的参数化知识可能对这些不同表述的问题产生不同的回答。这种差异可归因于LLM参数中嵌入的冲突知识,这些冲突源于复杂多样的预训练数据集中存在的不一致性。这就产生了论文称之为记忆内冲突(IM)的情况。
知识冲突最初源于开放域问答研究。这个概念在Longpre等人(2021年)的研究中引起了关注,该研究聚焦于参数化知识与外部段落之间的基于实体的冲突。同时,多个段落之间的差异也随后受到了仔细审查。随着大型语言模型(LLMs)的最近出现,知识冲突引起了极大的关注。例如,近期研究发现LLMs既坚持参数化知识,又容易受到上下文影响,当这种外部知识在事实上不正确时,这可能会产生问题。考虑到这对LLMs的可信度、实时准确性和稳健性的影响,深入理解和解决知识冲突变得至关重要。
论文将知识冲突的生命周期概念化为导致各种行为的原因,同时也是源于知识复杂本质的结果,如图2所示。知识冲突作为原因和模型行为之间的重要中介。例如,它们显著地导致模型生成事实上不正确的信息,即所谓的"幻觉"。论文的研究,以类似于弗洛伊德精神分析的方式,强调了理解这些冲突起源的重要性。尽管现有的分析倾向于人为构建这些冲突,但论文认为这些分析并未充分解决问题的相互关联性。
除了回顾和分析原因和行为之外,论文更深入地提供了解决方案的系统性综述,这些方案用于最小化知识冲突的不良后果,即鼓励模型展现符合特定目标的期望行为(请注意,这些目标可能因特定场景而异)。基于与潜在冲突相对的时间,策略分为两类:预先策略和事后策略。它们之间的关键区别在于是在潜在冲突出现之前还是之后进行调整。
知识冲突的分类如图3所示。论文依次讨论三种知识冲突,详细说明每种冲突的原因、模型行为分析,以及根据各自目标组织的可用解决方案。相关数据集可在表1中找到。
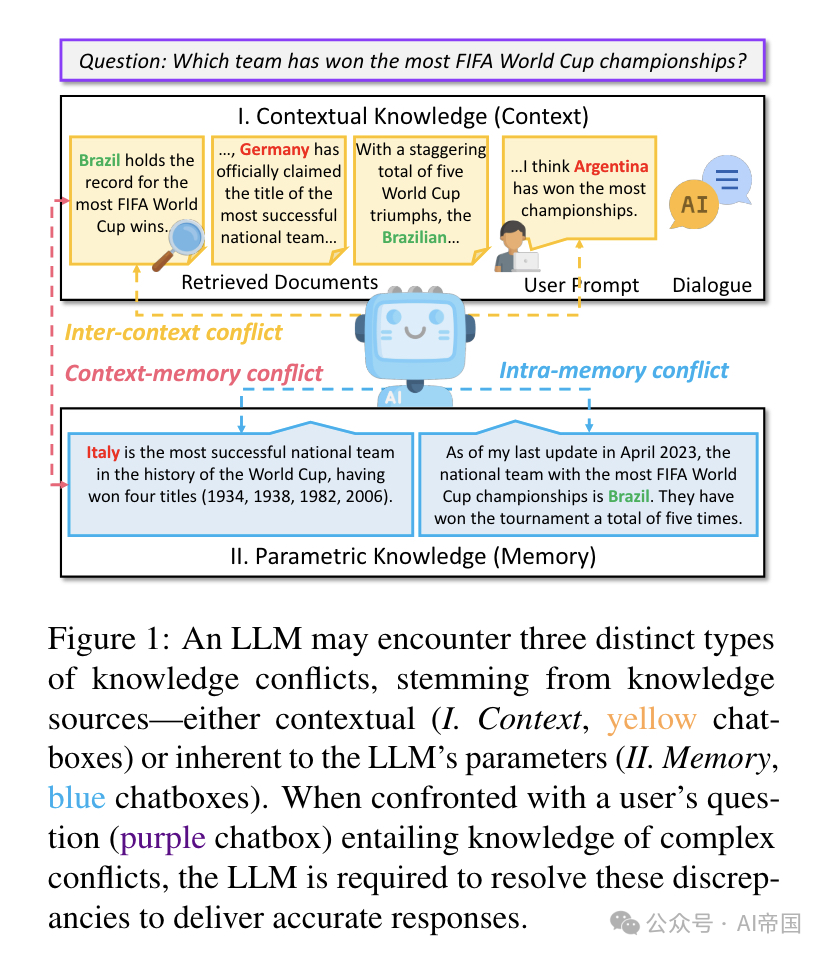
图1 展示了大型语言模型(LLM)可能遇到的三种不同类型的知识冲突,这些冲突源自知识来源——无论是上下文相关的(I. 上下文,黄色聊天框)还是固有于LLM参数中的(II. 记忆,蓝色聊天框)。当面对用户的提问(紫色聊天框),涉及复杂的知识冲突时,LLM需要解决这些差异以提供准确的回答
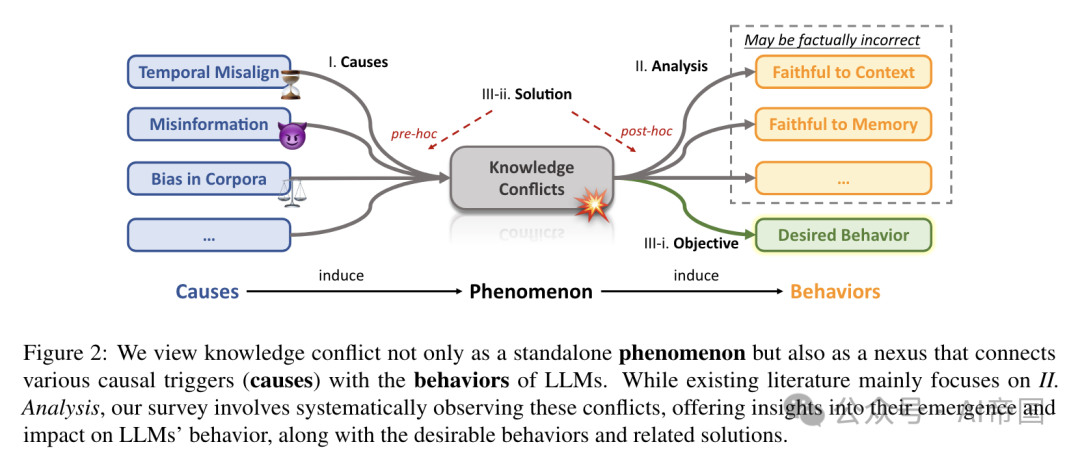
图2:论文将知识冲突不仅视为一个独立现象,而且视为连接各种因果触发因素(原因)与大型语言模型(LLMs)行为的纽带。尽管现有文献主要关注分析,论文的调查系统地观察这些冲突,提供对其产生及对LLMs行为影响的洞察,以及期望行为和相关解决方案
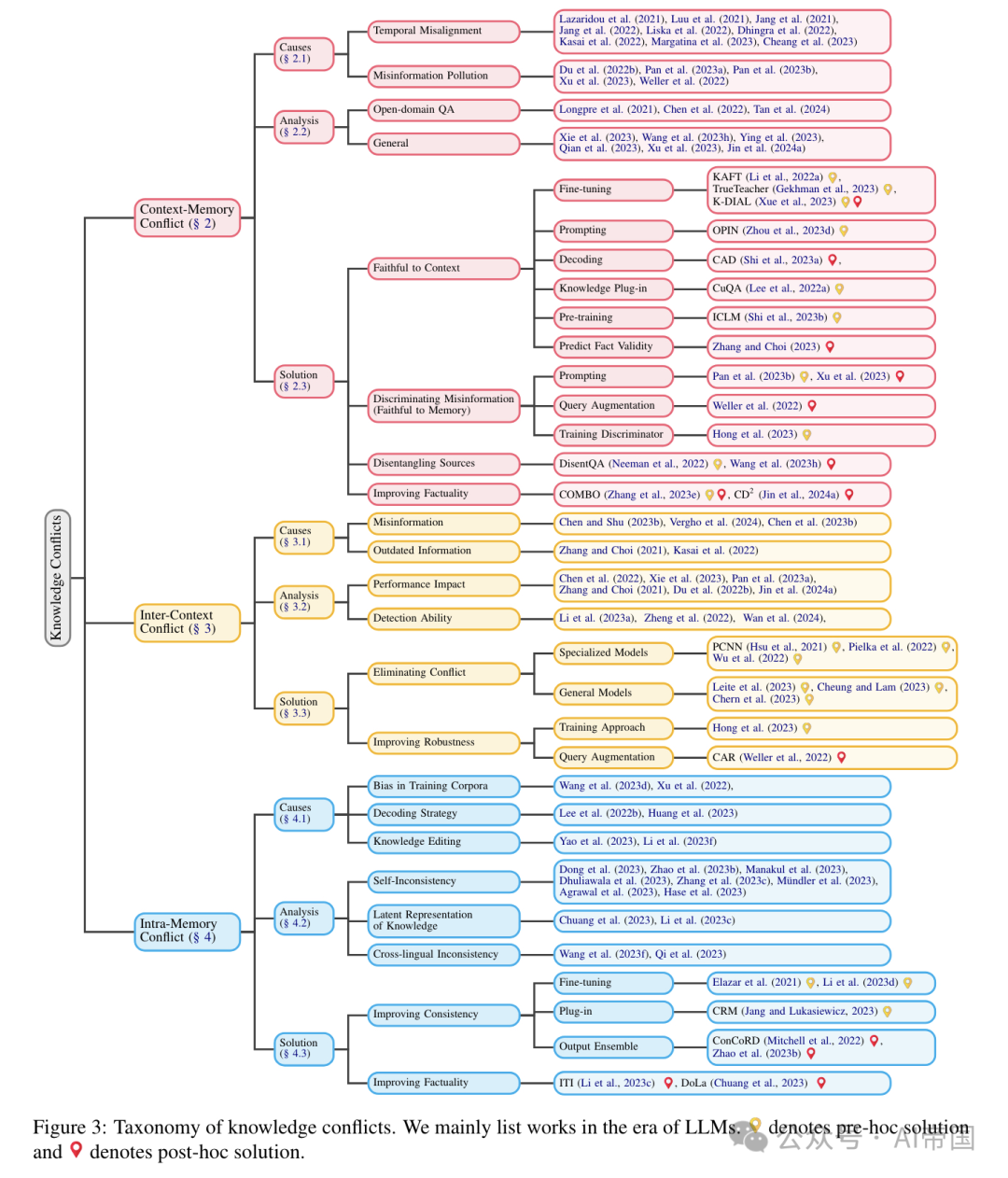
图 3:知识冲突的分类。论文主要列出了在大语言模型时代的工作。9 表示预先解决方案,而 9 表示事后解决方案

表1:评估大型语言模型在遇到知识冲突时的行为的数据集。CM:上下文-记忆冲突,IC:跨上下文冲突,IM:内部记忆冲突
2.2 上下文-记忆冲突(Context-Memory Conflict)
上下文-记忆冲突是三种冲突中研究最广泛的。大型语言模型(LLMs)的特点是其固定的参数知识,这是大量相关处理的结果。这种静态的参数知识与外部信息的动态性质形成鲜明对比,后者以快速的速度进化。
2.2.1 原因
上下文-记忆冲突的核心源于上下文与参数知识之间的差异。论文考虑两个主要原因:时间错位和错误信息污染。
时间错位。时间错位在以往数据训练的模型中自然出现,因为它们可能无法准确反映当代或未来的现实情况(即部署后的上下文知识)。这种错位会随着时间的推移降低模型的性能和相关性,因为它可能无法捕捉新的趋势、语言使用的变化、文化变迁或知识更新。研究者指出,时间错位导致模型在各种 NLP 任务上的性能下降。此外,由于预训练范式和扩大模型规模相关成本的增加,时间错位问题预计会加剧。
先前的工作试图通过关注三种策略来解决时间错位问题:
•知识编辑(KE)旨在直接更新现有预训练模型的参数知识。
•检索增强生成(RAG)利用检索模块从外部资源(如数据库、网络)获取相关文档,以补充模型的知识而不改变其参数。
•持续学习(CL)寻求通过在新数据和更新数据上持续预训练来更新内部知识。然而,这些缓解时间错位的方法并非万能。
KE可能引入知识冲突的副作用,导致知识不一致(即一种内部记忆冲突),甚至可能增强大型语言模型(LLMs)的幻觉。对于RAG,由于模型参数未更新,知识冲突不可避免(。CL面临灾难性遗忘问题,并需要大量计算资源。
Context-Memory Conflict 作为导致上下文记忆冲突的另一个因素出现,特别是对于模型已准确学习的时间不变知识。对手通过在检索文档的网络语料库中引入虚假或误导性信息来利用这一漏洞和用户对话。后者构成实际威胁,因为对手可以利用诸如提示注入攻击等技术。这一漏洞构成真实威胁,因为模型可能在不加审查地吸收欺骗性输入的情况下无意中传播虚假信息。
研究者观察到,制造的恶意错误信息能显著削弱自动化事实核查系统和开放领域问答模型的准确性。此外,近期研究也强调了模型倾向于迎合用户观点,即所谓的“谄媚”,这进一步加剧了问题。在当前的大型语言模型(LLMs)领域,自然语言处理(NLP)社区对于LLMs可能产生的错误信息日益担忧。研究者认识到检测由LLMs生成的错误信息所面临的挑战。这突显了在上下文错误信息的背景下,解决LLMs带来的微妙挑战的紧迫性。
2.2.2 模型行为的分析
LLMs如何处理上下文记忆冲突?本节将详细介绍相关研究,尽管它们提供了相当不同的答案。根据情景,论文首先介绍开放领域问答(ODQA)设置,然后关注一般设置。
ODQA:
•在早期的ODQA文献中,Longpre等人(2021)探讨了当提供的上下文信息与已学习的信息相矛盾时,问答模型如何表现。作者们开发了一个自动化框架,该框架能够识别出答案为命名实体的QA实例,并将黄金文档中提及该实体的部分替换为另一个实体,从而创建冲突上下文。这项研究揭示了这些模型过度依赖参数知识的倾向。
•Chen等人(2022)重新审视了这一设置,并报告了不同的观察结果,他们指出,在最佳表现设置中,模型主要依赖于上下文知识。他们将这种发现上的差异归因于两个因素。首先,Longpre等人(2021)使用的实体替换方法可能降低了受干扰段落的语义连贯性。其次,Longpre等人(2021)的研究基于单一证据段落,而Chen等人(2022)则利用了多个证据段落。
•最近,随着ChatGPT(Ouyang等人, 2022; OpenAI, 2023)和Llama 2(Touvron等人, 2023)等早期大型语言模型的出现,研究人员重新审视了这一问题。
•Tan等人(2024)研究了在ODQA设置中,LLM如何融合检索到的上下文与生成的知识,并发现模型倾向于偏好参数知识,这是受到这些生成上下文与输入问题更相似以及检索信息往往不完整的影响,尤其是在冲突来源的范围内。
概述:
•Xie等人(2023年)利用大型语言模型(LLMs)生成与记忆知识相冲突的上下文。他们发现,语言模型对与外部证据高度敏感,即使这些证据与其参数化知识相冲突,只要外部知识连贯且令人信服。同时,他们也识别出LLMs中存在强烈的确认偏误(Nickerson, 1998),即模型倾向于偏爱与内部记忆一致的信息,即使面对冲突的外部证据。
•Wang等人(2023g)提出,当LLM遇到冲突时,理想的行为应该是准确定位冲突并提供明确的答案。他们发现,尽管LLMs在识别知识冲突的存在方面表现良好,但在确定具体的冲突片段并在冲突信息中产生明确答案时遇到困难。
•Ying等人(2023年)分析了LLMs在冲突情况下的鲁棒性,重点关注两个方面:事实鲁棒性(从提示或记忆中识别正确事实的能力)和决策风格(根据认知理论将LLMs的行为分类为直觉型、依赖型或理性型)。研究发现,LLMs极易受到误导性提示的影响,尤其是在常识知识的背景下。
•Qian等人(2023年)更系统地评估了参数化知识与外部知识之间潜在的交互作用,合作知识图谱(KG)。他们揭示,当面对直接冲突或详细上下文变化时,LLMs常常偏离其参数化知识。
•Xu等人(2023年)研究了大型语言模型(LLMs)在交互会话中如何应对知识冲突。他们的发现表明,LLMs倾向于偏爱逻辑结构化的知识,即使这与事实准确性相矛盾。
2.2.3 解决方案
解决方案根据其目标进行组织,即论文期望LLM在遇到冲突时表现出的预期行为。现有的策略可以归类为以下目标:忠实于上下文的策略旨在与上下文知识保持一致,侧重于上下文优先级。鉴别错误信息的策略鼓励对可疑上下文持怀疑态度,倾向于参数知识。分离来源的策略将上下文和知识分开处理,并提供解耦的答案。提高事实性的策略旨在利用上下文和参数知识整合回答,以实现更真实的解决方案。
忠实于上下文。
•微调。Li等人(2022a)认为,LLM应优先考虑上下文中的任务相关信息,并在上下文无关时依赖内部知识。他们将这两种属性称为可控性和鲁棒性。他们引入了知识感知微调(KAFT),通过将反事实和无关上下文纳入标准训练数据集来加强这两种属性。Gekhman等人(2023)介绍了TrueTeacher,该方法通过使用LLM对模型生成的摘要进行标注,专注于提高摘要的事实一致性。这种方法有助于保持对原始文档上下文的忠诚度,确保生成的摘要准确无误,不会被无关或错误细节误导。DIAL(Xue等人, 2023)专注于通过直接知识增强和RLFC(强化学习事实校验)来提高对话系统的事实一致性,以准确地使响应与提供的事实知识对齐。
•提示策略。Zhou等人(2023d)探讨了通过专门的提示策略增强大型语言模型(LLMs)对上下文的遵守,特别是基于意见的提示和反事实演示。这些技术通过确保LLMs忠实于相关上下文,显著提高了在上下文敏感任务中的表现,无需额外训练。
•解码技术。Shi等人(2023a)引入了上下文感知解码(Context-aware Decoding, CAD),通过放大有无上下文时的输出概率差异来减少幻觉,这与对比解码(Li等人,20220)的概念相似。CAD通过有效地优先考虑相关上下文而非模型的先验知识,特别是在信息冲突的任务中,增强了LLMs的忠实度。
•知识插件。Lee等人(2022a)提出了持续更新的问答(Continuously-updated QA, CuQA),以提高语言模型(LMs)整合新知识的能力。他们的方法使用即插即用模块来存储更新的知识,确保原始模型不受影响。与传统的持续预训练或微调方法不同,CuQA能够解决知识冲突。
•预训练。ICLM(Shi等人,2023b)是一种新的预训练方法,扩展了LLMs处理跨多个文档的长而多变的上下文的能力。这种方法通过使模型能够从更广泛的上下文中综合信息,可能有助于解决知识冲突,从而提高对相关知识的理解和应用。
•预测事实有效性。Zhang和Choi(2023)通过引入事实持续时间预测来识别并丢弃LLMs中的过时事实,解决了知识冲突问题。这种方法通过确保遵守最新的上下文信息,提高了在开放域问答(ODQA)等任务中的模型性能。
辨别错误信息(忠于记忆)。
•提示。为了应对错误信息污染,Pan等人(2023b)提出了诸如错误信息检测和警觉提示等防御策略,旨在增强模型在潜在错误信息中保持对事实、参数化信息忠实的能力。同样,Xu等人(2023)利用系统提示提醒大型语言模型(LLM)对潜在错误信息保持谨慎,并在回应前验证其记忆的知识。这种方法旨在提升LLM保持忠实性的能力。
•查询增强。Weller等人(2022)利用大型语料库中信息冗余性来防御错误信息污染。他们的方法涉及查询增强以找到一组多样化的不太可能被污染的段落,并结合一种名为“答案冗余信心”(CAR)的方法,该方法比较预测答案在检索上下文中的连贯性。这一策略通过确保模型在多个来源中交叉验证答案的忠实性来缓解知识冲突。训练鉴别器:Hong等人(2023)对一个较小的语言模型进行微调,作为鉴别器,并结合提示技术,发展模型的能力以区分可靠与不可靠信息,帮助模型在面对误导性上下文时保持忠实。
分离来源。DisentQA(Neeman等人,2022)训练一个模型,为给定问题预测两种类型的答案:一种基于上下文知识,另一种基于参数化知识。Wang等人(2023g)引入了一种方法来改进LLM处理知识冲突的能力。他们的方法是一个三步流程,旨在帮助LLM检测冲突、准确识别冲突段落,并基于冲突数据生成明确的、有根据的回应,旨在产生更精确和细致的模型输出。
提高事实准确性。Zhang等人(2023e)提出了COMBO框架,该框架通过匹配兼容的生成和检索段落来解决差异。它使用在银标上训练的判别器来评估段落兼容性,通过利用LLM生成的(参数化)和外部检索的知识来提高开放域问答(ODQA)的性能。Jin等人(2024a)引入了一种基于对比解码的算法,即CD?,该算法在知识冲突下最大化不同逻辑之间的差异,并校准模型对真实答案的信心。
2.3 上下文间冲突(Inter-Context Conflict)
上下文间冲突在LLMs中体现为整合外部信息源时出现的问题,这一挑战因RAG技术的出现而加剧。RAG通过将检索到的文档内容整合到上下文中来丰富LLM的响应。然而,这种整合可能导致提供上下文内的不一致,因为外部文档可能包含相互冲突的信息。
2.3.1 原因
错误信息。错误信息一直是现代数字时代的一个重大关切。RAG的出现引入了一种新的方法,通过整合外部文档来提高LLMs的生成质量。虽然这种方法有可能通过多样化的知识源丰富内容,但也带来了包含错误信息文档的风险,如假新闻。此外,已有案例表明AI技术被用于创建或传播错误信息。LLMs的先进生成能力加剧了这一问题,导致这些系统生成的错误信息增加。这一趋势令人担忧,因为它不仅助长了错误信息的传播,还挑战了检测由LLMs生成的错误信息的能力。
过时信息。除了错误信息的挑战外,认识到事实随时间变化,这一点也很重要。检索到的文档可能同时包含来自网络的更新信息和过时信息,导致这些文档之间出现冲突。
2.3.2 模型行为分析
性能影响。先前的研究实证表明,预训练语言模型的性能可以显著受到特定上下文中错误信息(Zhang 和 Choi,2021)或过时信息(Du 等人,2022b)的存在的影响。
•在最近的研究中,Pan 等人(2023a)引入了一种错误信息攻击策略,涉及创建维基百科文章的伪造版本,随后将其插入到真实的维基百科语料库中。他们的研究结果揭示,现有的语言模型容易受到错误信息攻击,无论假文章是手工制作还是模型生成的。
•为了深入了解LLMs在遇到矛盾上下文时的行为,Chen 等人(2022)主要使用解码器中的融合技术在NQ-Open(Kwiatkowski 等人,2019)和TriviaQA(Joshi 等人,2017)上进行实验。他们发现,跨知识源的不一致对模型的置信度影响最小。这些模型倾向于偏好与查询直接相关的上下文和与模型固有参数知识一致的上下文。
•Xie 等人(2023)在POPQA(Mallen 等人,2022)和STRATEGYQA(Geva 等人,2021)上对闭源LLMs和开源LLMs进行了实验。得到的结果与Chen 等人(2022)的结果一致,表明LLMs对与模型参数记忆一致的证据表现出显著的偏见。他们还发现,LLMs倾向于强调与更高知名度实体相关的信息和在给定上下文中由更大体积文档证实的答案。
•此外,这些模型对数据引入的顺序表现出显著的敏感性。Jin 等人(2024a)发现,随着冲突跳数的增加,LLMs在推理方面遇到更大的挑战。
Detection Ability 在评估大型语言模型(LLMs)面对矛盾上下文时的表现之外,多项研究还探讨了它们识别此类矛盾的能力。
•郑等人(2022)检验了包括BERT、RoBERTa和ERNIE在内的多种模型在识别中文对话中矛盾陈述的表现。其实验结果显示,识别对话中的矛盾语句对这些模型来说是一个重大挑战。
•李等人(2023a)分析了GPT-4、ChatGPT、PaLM-2和Llama 2在识别新闻文章(Hermann et al., 2015)、故事(Kocisky et al., 2018)及维基百科(Merity et al., 2017)中矛盾文档的表现。研究者发现,平均检测准确率不尽如人意。该研究还指出,LLMs在处理特定类型的矛盾时面临特殊挑战,尤其是涉及主观情感或观点的矛盾。
•此外,文档的长度和自相矛盾的多样性对检测性能的影响较小。万等人(2024)研究了影响LLMs在面对冲突信息时评估文档可信度的文本特征。他们发现,现有模型严重偏向于文档与查询的相关性,但往往忽视了人类认为重要的风格特征,如文本中科学引用的存在或中立语调。
•金等人(2024a)发现,LLMs在区分真实信息与虚假信息方面存在困难。此外,他们发现LLMs倾向于支持在上下文中出现频率最高的证据,并对外部信息表现出确认偏误,这些信息与其内部记忆相符。
2.3.3解决方案
消除冲突。专业化模型。Hsu等人(2021)开发了一种名为成对矛盾神经网络(PCNN)的模型,利用微调的Sentence-BERT嵌入来计算文章之间的矛盾概率。Pielka等人(2022)建议将语言学知识融入学习过程中,基于发现XLM-RoBERTa难以有效掌握对于准确矛盾检测至关重要的句法和语义特征。Wu等人(2022)提出了一种创新方法,将文本的拓扑表示整合到语言模型中,以增强矛盾检测能力,并在MultiNLI数据集(Williams等人,2018)上评估了他们的方法。
通用模型。Chern等人(2023)提出了一种事实核查框架,该框架将大型语言模型(LLMs)与各种工具(包括Google搜索、Google Scholar、代码解释器和Python)集成,用于检测文本中的事实错误。Leite等人(2023)利用LLMs为输入文本生成与预定义可信度信号相关的弱标签,并通过弱监督技术聚合这些标签,以对输入的真实性做出预测。
提高鲁棒性。训练方法。Hong等人(2023)提出了一种新颖的微调方法,涉及同时训练一个判别器和一个解码器,使用共享的编码器。此外,作者还引入了另外两种策略来提高模型的鲁棒性,包括提示GPT-3在生成响应之前识别受扰动的文档,以及将判别器的输出整合到GPT-3的提示中。他们的实验结果表明,微调方法产生了最令人满意的结果。
查询增强技术 如Augmentin等人(2023)所述,通过提示GPT-3根据原始查询生成新的问题。随后,他们通过参考检索到的相应段落来评估每个问题答案的置信度。基于这种置信度,他们决定是依赖原始问题的预测,还是汇总来自增强问题且置信度得分高的预测。
2.4 内部记忆冲突(Intra-Memory Conflict)
随着LLMs的发展,LLMs被广泛应用于知识密集型问答系统(Gao等人,2023b;Yu等人,2022;Petroni等人,2019;Chen等人,2023c)。有效部署LLMs的一个关键方面是确保它们对具有相似含义或意图的各种表达产生一致的输出。尽管有此必要,但内部记忆冲突——LLMs对语义上等效但句法上不同的输入表现出不可预测的行为并生成不同响应的情况——成为一个显著挑战(Chang和Bergen,2023;Chen等人,2023a;Raj等人,2023;Rabinovich等人,2023;Raj等人,2022;Bartsch等人,2023)。内部记忆冲突实质上通过在其输出中引入不确定性,削弱了LLMs的可靠性和实用性。
2.4.1 原因
LLMs中的内部记忆冲突可归因于三个主要因素:训练语料库偏差(Wang等人,2023d;Xu等人,2022)、解码策略(Lee等人,2022b;Huang等人,2023)和知识编辑(Yao等人,2023;Li等人,2023f)。这些因素分别涉及训练阶段、推理阶段和随后的知识精炼。
训练语料库中的偏差。最近的研究表明,大型语言模型(LLMs)知识获取的主要阶段主要发生在预训练阶段(Zhou et al., 2023a; Kaddour et al., 2023; Naveed et al., 2023; Akyiüirek et al., 2022; Singhal et al., 2022)。预训练语料库主要从互联网上爬取,数据质量多样,可能包含不准确或误导性信息(Bender et al., 2021; Weidinger et al., 2021)。当LLMs在包含错误知识的数据上训练时,它们可能会记忆并无意中放大这些不准确之处(Lin et al., 2022; Elazar et al., 2022; Lam et al., 2022; Grosse et al., 2023),导致LLMs参数内部冲突知识并存的情况。
此外,先前的工作表明,LLMs倾向于在其训练数据中编码普遍存在的表面关联,而不是真正理解其中包含的基础知识(Li et al., 2022b; Kang and Choi, 2023; Zhao et al., 2023a; Kandpal et al., 2023)。这可能导致LMs表现出一种倾向,即基于训练数据的虚假相关性生成预定响应。由于依赖于虚假相关性,当面对具有不同句法结构但传达相同语义意义的提示时,LLMs可能会提供不同的答案。
解码策略。大型语言模型(LLMs)的直接输出是对潜在下一个词的概率分布。从这一分布中抽样是确定生成内容的关键步骤。已提出了多种抽样技术,包括贪心抽样、top-p抽样、top-k抽样等(Jawahar et al., 2020; Massarelli et al., 2020),大致可分为确定性和随机性抽样方法。随机抽样作为LLMs普遍采用的解码策略(Fan et al., 2018; Holtzman et al., 2020)。然而,随机抽样方法的随机性引入了生成内容的不确定性。此外,由于LLMs固有的从左到右生成模式,抽样词的选择对后续生成内容具有重大影响。使用随机抽样可能导致LLMs在相同上下文下产生完全不同的内容,引发内部记忆冲突(Lee et al., 2022b; Huang et al., 2023; Dziri et al., 2021)。
知识编辑。随着模型参数的指数级增长,微调LLMs变得越来越困难且资源密集。针对这一挑战,研究者探索了知识编辑技术,作为高效修改LLMs中编码知识的一小部分的方法(Meng et al., 2022; Ilharco et al., 2022; Zhong et al., 2023)。确保修改的一致性是一个重大挑战。由于编辑方法可能存在的局限性,修改后的知识无法有效泛化。这可能导致LLMs在处理不同情境下相同知识时产生不一致的响应(Li et al., 2023f; Yao et al., 2023)。内部记忆冲突主要被视为知识编辑过程中的副作用。
备注:大型语言模型(LLMs)中的内存内部冲突源于三个不同阶段的独特原因。在这些原因中,训练语料库偏差尤为突出,是这些冲突的根本催化剂。训练数据集中知识的矛盾导致模型参数内编码的知识不一致。此外,解码策略间接加剧了这些冲突。推理过程中采样过程的固有随机性放大了模型响应中的不一致性。知识编辑旨在对模型的知识进行后更新,但可能无意中将冲突信息引入LLM的内存中。
2.4.2 模型行为的分析
自相矛盾。Elazar等人(2021)开发了一种评估语言模型知识一致性的方法,特别关注知识三元组。研究者主要使用BERT、RoBERTa和ALBERT进行实验。结果显示,这些模型的准确率仅在50%至60%之间,表现出较差的一致性。Hase等人(2023)采用了Elazar等人(2021)相同的指标,但使用了更多样化的数据集。他们的研究也揭示了RoBERTa-base和BART-base在改写上下文中的不一致性。Zhao等人(2023b)重新表述问题,然后评估LLM对这些重新表述问题的响应的一致性。研究发现,即使在常识性问答任务中,GPT-4也显示出13%的显著不一致率。他们进一步发现,LLMs在面对不常见知识时更容易产生不一致。Dong等人(2023)对多个开源LLMs进行了实验,发现所有这些模型都表现出强烈的不一致性。Li等人(2023d)探讨了LLMs可能给出的初始答案与随后否认先前答案的不一致性。研究者专注于闭卷问答实验,揭示了Alpaca-30B仅在50%的情况下表现出一致性。
为了进一步分析大型语言模型(LLMs)表现出的不一致性,Li等人(2022b)进行的一项研究发现,基于编码器的模型更依赖于位置上接近且高度共现的词汇来生成错误的事实性词汇,而不是依赖于知识相关的词汇。这种现象是由于这些模型倾向于从训练数据集中过度学习不恰当的关联。Kang和Choi(2023)强调了LLMs中的共现偏差,其中模型倾向于偏好频繁共现的词汇而非正确答案,尤其是在回忆事实时,即使经过微调,主题和对象在预训练数据集中很少共现的情况下。此外,他们的研究表明,即使在微调过程中遇到这些事实,LLMs在主题和对象很少一起出现在预训练数据集中的情况下回忆事实仍然面临挑战。
知识潜表示。当代LLMs固有的多层变换器架构促进了复杂的内部记忆冲突,不同的知识表示散布在各个层次。先前的研究建议,LLMs在较浅层次存储低级信息,在较深层次存储语义信息(Tenney et al., 2019; Rogers et al., 2020; Wang et al., 2019; Jawahar et al., 2019; Cui et al., 2020)。Chuang等人(2023)在LLMs的背景下探讨了这一点,并发现LLMs中的事实知识通常集中在特定的变换器层和不同层的不一致知识中。此外,Li等人(20230)发现,正确的知识确实存储在模型的参数中,但在生成过程中可能无法准确表达。作者对同一LLM进行了两项实验,一项关注生成准确性,另一项使用知识探针来检查知识的包含情况。这些实验的结果显示,知识探针准确性与生成准确性之间存在显著的40%差异。
跨语言不一致性 真正的知识普遍性超越了表面形式的变异(Ohmer 等人,2023),这一原则理想上应适用于大型语言模型(LLMs)。然而,LLMs 对不同语言保持了不同的知识集,导致了不一致性(Ji 等人,2023)。Wang 等人(2023e)研究了 LLMs 在跨语言扩展编辑知识时面临的挑战,表明与不同语言相关的知识在模型参数中被单独存储。Qi 等人(2023)提出了一种名为 RankC 的度量标准,用于评估 LLMs 事实知识的跨语言一致性。他们利用这一度量分析了多个模型,并揭示了 LLMs 存储的知识中存在明显的语言依赖性,且随着模型规模的增加,跨语言一致性并未观察到改善。
备注 LLMs 中的内存间冲突现象主要通过对语义相同查询的不一致响应来体现。这种不一致性主要归因于预训练阶段使用的数据集质量不佳。解决这一挑战需要开发高效且成本有效的解决方案,这仍然是一个重大障碍。此外,LLMs 的特点是存在多个知识电路,这些电路对其对特定查询的响应机制有显著影响。探索和详细检查 LLMs 内部的知识电路代表了一个有前景的未来研究方向。
2.4.3解决方案
2.4.3.1 提高一致性
微调。Elazar 等人(2021)提出了一种一致性损失函数,并使用一致性损失与标准 MLM 损失的组合来训练语言模型。Li 等人(2023d)利用一种语言模型在双重能力下运作:作为生成器产生响应,并作为验证器评估这些响应的准确性。该过程涉及向生成器查询响应,随后由验证器评估其准确性。只有那些被认为一致的响应对被保留。这一组一致的响应对随后用于微调模型,旨在增加生成一致响应对的概率。
插件。Jang 和 Lukasiewicz(2023)利用中间训练技术,使用词典中的词-定义对重新训练语言模型,以提高其对符号意义的理解。随后,他们提出了一种高效的参数集成方法,将这些增强的参数与现有语言模型的参数合并。这种方法旨在通过增强模型理解意义的能力来纠正模型的不一致行为。
输出集成。Mitchell等人(2022)提出了一种通过采用双模型架构来减轻语言模型不一致性的方法,该架构涉及使用一个基础模型负责生成一组潜在答案,随后由关系模型评估这些答案之间的逻辑一致性。最终答案的选择考虑了基础模型和关系模型的信念。Zhao等人(2023b)引入了一种方法来检测问题是否可能导致大型语言模型(LLMs)的不一致性。具体而言,他们首先使用LLMs重述原始问题并获得相应的答案,然后对这些答案进行聚类并检查分歧程度。检测结果基于分歧水平确定。
2.4.3.2 提高事实性
Chuang等人(2023)提出了一种名为DoLa的新型对比解码方法。具体地,作者开发了一种动态层选择策略,选择适当的早期层和成熟层。接下来单词的输出概率通过计算早期层和成熟层对数概率的差异来确定。Li等人(2023c)提出了一种类似的方法名为ITI。他们首先识别出一批稀疏的注意力头,这些头在TruthfulQA(Lin等人,2022)衡量的事实性方面表现出高线性探测准确性。在推理阶段,ITI沿着通过知识探测获得的与事实相关的方向调整激活,这种干预在完成过程中对每个令牌进行自回归重复。DoLa和ITI都针对模型不同层之间的知识不一致性,以减少LLMs中的事实错误。

姜鎮英

陳钧铭

郭繁夏

艾红梅

陈岳云
- 新加坡国立大学仇成伟教授:意...
- 托马斯·弗里德曼:中美关系究...
- 2023美国USNEWS最佳...
- 哈佛读博 残疾中国姑娘逆袭人...
- 2023年CSC与有关国际组...
- 美国国家侦察局(NRO):计...
- 剑桥大学设计出低成本、高能效...
- 美国晨光基金会2023年奖助...
- 哥伦比亚大学与百人会联合发布...
- 2023年中国毒情形势报告...
- 2023WRWU世界大学排名...
- 为什么中国基础研究难获诺贝尔...
- 四个中立国家倒戈,转向军援乌...
- 美国安顾问沙利文在布鲁金斯学...
- 2023年全球最佳医院排行榜...
- 密歇根州立大学博士生身穿自己...
- 让HIV无法进入细胞 麻省总...
- 《天体物理学杂志快报》:全分...
- 美国西来大学陈岳云教授:40...
- 伦敦大学学院教授唐军旺院士实...
- 德国马克斯·普朗克太阳系研究...
- 谷歌科学家Natasha J...
- 中国教育部、海南省《境外高等...
- ChatGPT助力科研:智能...
- 洛杉磯西來大学欢迎您!...
- 2023年5月美国移民排期进...
- 2023年(第十五届)苏州国...
- 直接读取人类思维的机器来了!...
- 2024年度日本政府(文部科...
- 我在印度生活8个月,摘下有色...

Scholars-Net is a 501(c)(3) non-profit organization. Check payable to CAPPA, P.O. Box 236, Barstow, CA 92312, or direct deposit to Cathay Bank, 9121 Bolsa Ave., Westminster, CA 92683. Account number: 0005479070